
오늘은 인과추론 분석 도구 중 하나인 RD(Regression Discontinuity ; 회귀 불연속 설계)에 대한 글을 써 보려고 한다. "회귀 불연속"이라는 단어가 다소 어려워 보이지만, 개념 자체는 가장 직관적이다.
아슬아슬하게 막차를 탄 사람과 막차를 타지 못한 사람을 비교한다면, 이 두 집단은 정말 간발의 차이밖에 나지 않을테니 둘을 비교하면 인과효과를 파악할 수 있다는 뜻이다.
조금 더 구체적으로 예시를 들면 수능 등급을 생각해볼 수 있을 것 같다.
분명 국어(라떼는 언어 영역이었지만..), 수학, 영어 모두 점수는 1점 단위이지만 등급은 1점 차이로 짤없이 갈린다.
만약 96점이 1등급 컷이었다고 하면, 95점이랑 96점은 1점이라는 미미한 차이밖에 나지 않지만,
등급 기준으로는 95점은 2등급, 96점은 1등급에 배정된다.
만일 수능 등급이 인생에 미치는 영향(...은 너무 거시적이고 추상적이지만)을 분석하겠다고 하면, "95점 - 96점 집단을 비교해서 인과 효과를 파악해보겠다!"는 게 바로 회귀 불연속 설계의 개념이라 할 수 있겠다.
본격적으로 RD에 대해 이야기하기 전에 몇 가지 용어에 대해 먼저 이야기하고 넘어가보려 한다.
RD 이해에 필요한 기본 용어
배정 변수(Running Variable)
- 처치 여부를 결정하는 변수로, 수능 등급 컷 예시에서는 점수라고 보면 될 것 같다.
- 수능등급(처치변수)은 오로지 점수에 의해서만 영향을 받는다.
계단형 RD (sharp RD)
- 배정변수가 임계치를 통과한다면 처치가 0% 또는 100%로 완벽하게 결정되는 상황을 의미한다.
- 수능 등급 컷도 계단형 RD인데, 점수에 따라 특정 등급이 100% 결정되기 때문이다.
경사형 RD (fuzzy RD)
- 계단형 RD와 달리 배정변수가 임계치를 통과한다면, 처치 여부가 결정될 확률이 높아지기는 하지만 100%는 아닌 상황을 의미한다.
- 등급 컷 예시는 경사형 RD는 아닌데, 95점인 학생 중 1등급은 30%, 2등급 70%, 96점인 학생 중 1등급 80%, 2등급 20% 이렇게 나오는 경우는 없기 때문이다.
임계치 전후로 처치 여부가 결정되는 상황은 굉장히 매력적이다. 특히 게임에서는 특정 값(예를 들어 레벨) 전후로 상황이 달라지는 경우가 많기 때문에 혹시 RD를 써먹을 수도 있지 않을까? 하는 입맛을 다시게 되는 경우가 많다.
내 레벨에 따라 특정 컨텐츠가 오픈되기도 하고,
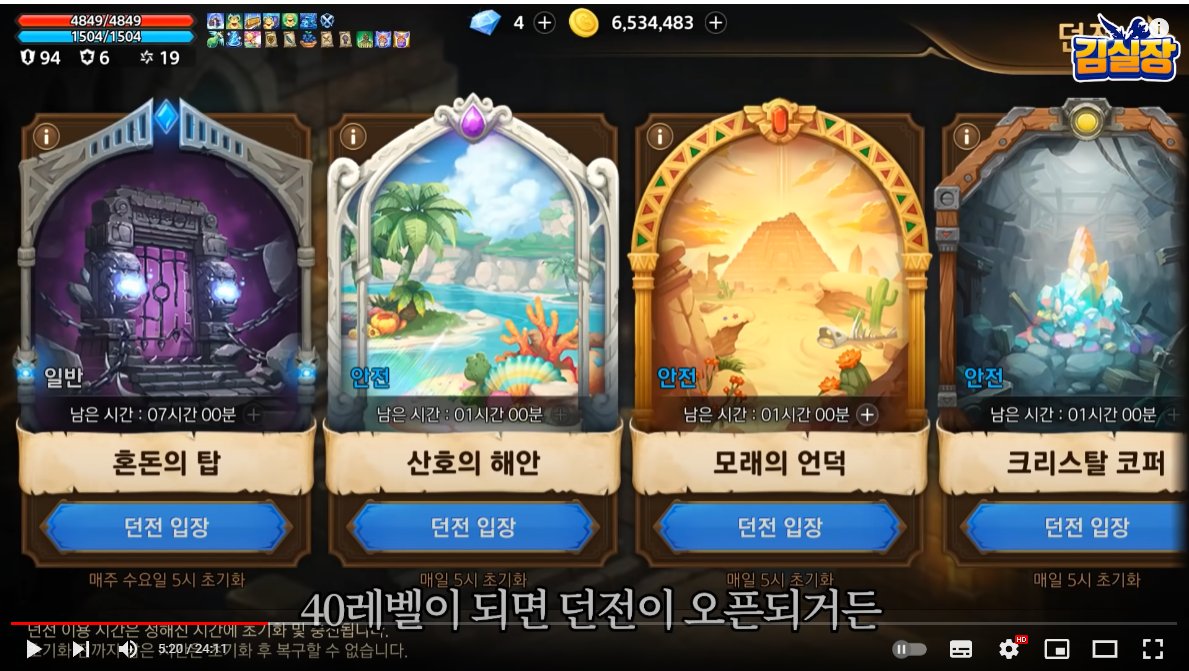
내가 진행한 스테이지 레벨에 따라 특정 컨텐츠가 오픈되기도 한다.
혹시 어떤 컨텐츠가 유저로 하여금 게임을 더 열심히 하도록 만드는 동기부여가 될 수 있지 않을까?
그리고 우리는 컨텐츠 개방조건을 아슬아슬하게 만족한 유저와 만족하지 못한 유저를 비교한다면 특정 컨텐츠의 동기 부여 효과를 분석할 수도 있지 않을까?

결론부터 말하면 굉장히 어렵다....
RD 분석 시 주의점
RD를 잘 써먹는다는 건 굉장히 힘든 일이다.
1. 어떤 함수를 쓸 건지(Functional Form)
2. 특정값 전후로 얼만큼의 구간을 사용할 것인지(bandwidth)
를 결정해야 하는데, 이게 생각보다 쉽지 않은 문제다.
이런 데이터를 갖고 있다고 가정해보자.

21 전후로 뭔가 패턴이 달라지는 것 같다는 생각이 든다. 그러면 어떻게 이 패턴을 설명하면 좋을까?
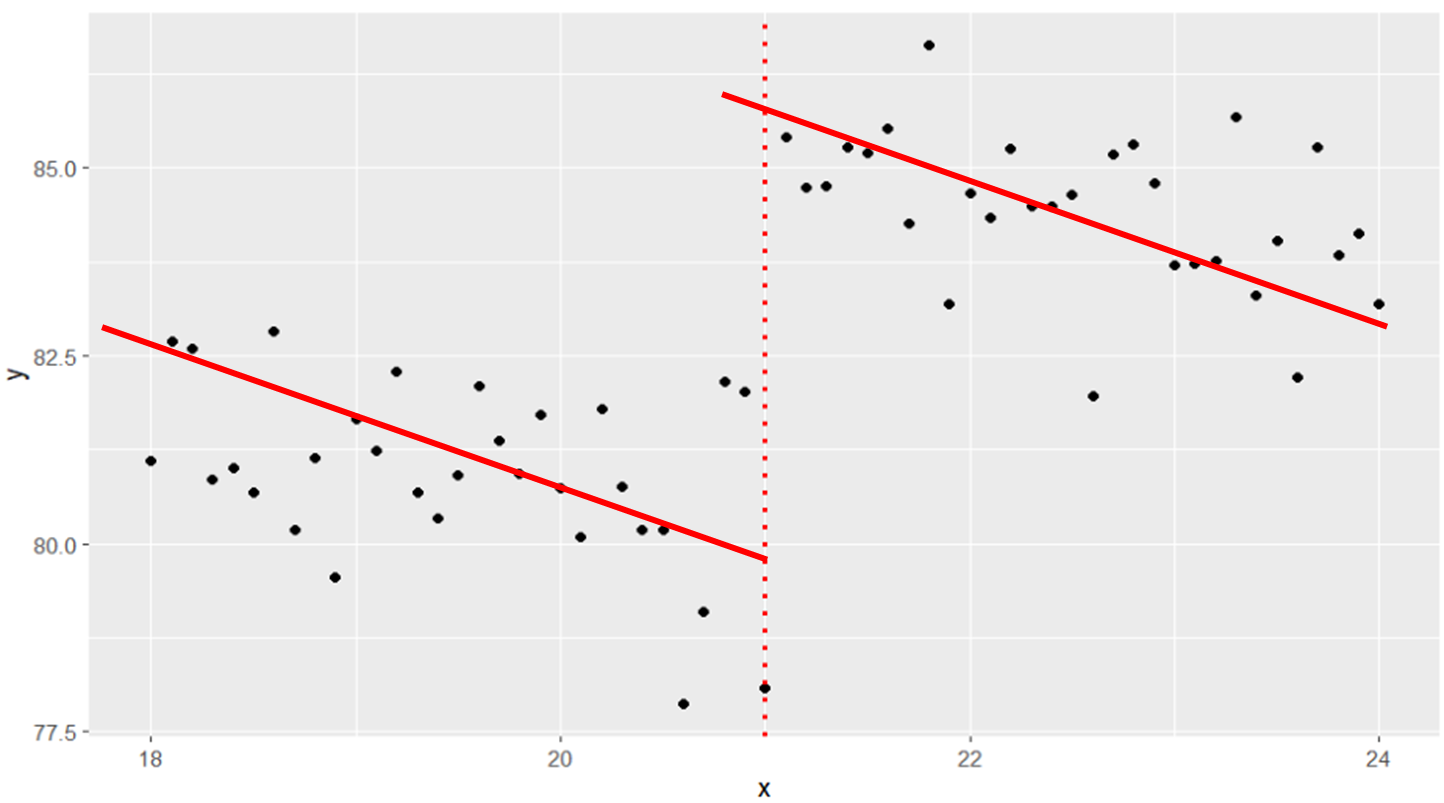
- 왼쪽 그림과 같이 해석하면 21이라는 값이 미치는 파급효과가 꽤 커보인다.
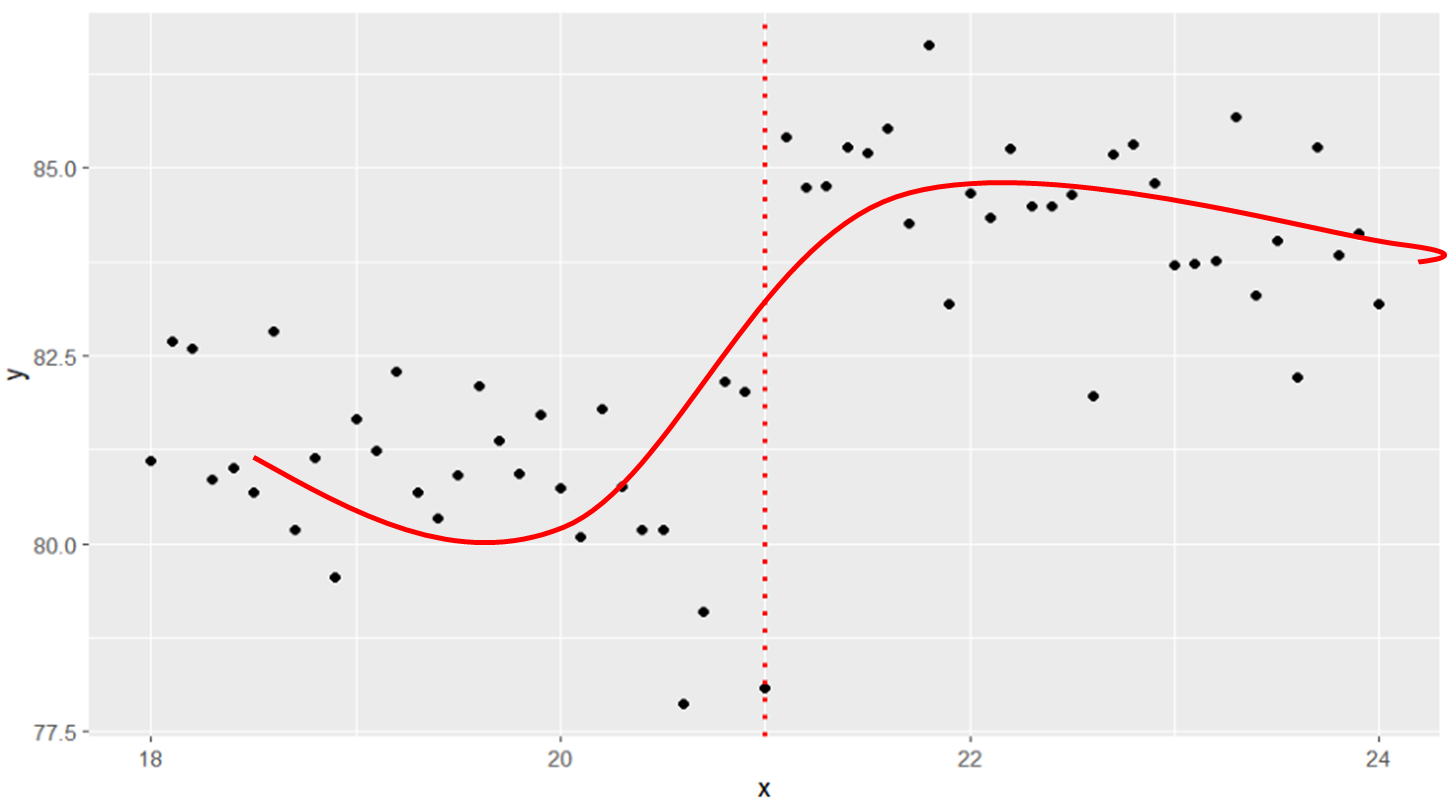
- 하지만 오른쪽 그림과 같이 해석하면 21이라는 값이 뭔가의 자연스러운 흐름으로, 그다지 중요한 값으로 보이지는 않는다.
또 특정값 전후로 구간을 얼마나 잡느냐도 해석이 크게 달라질 수 있는데,
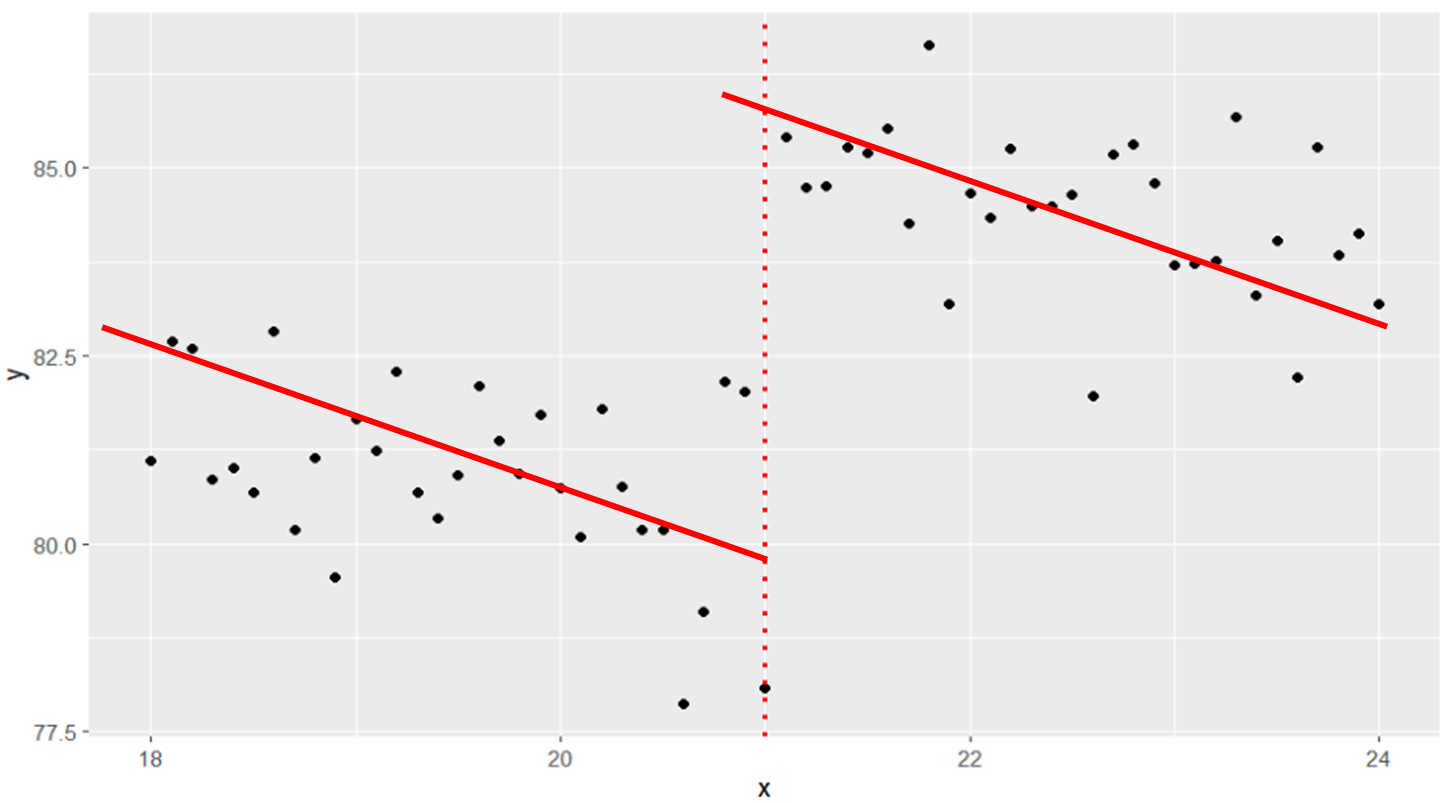
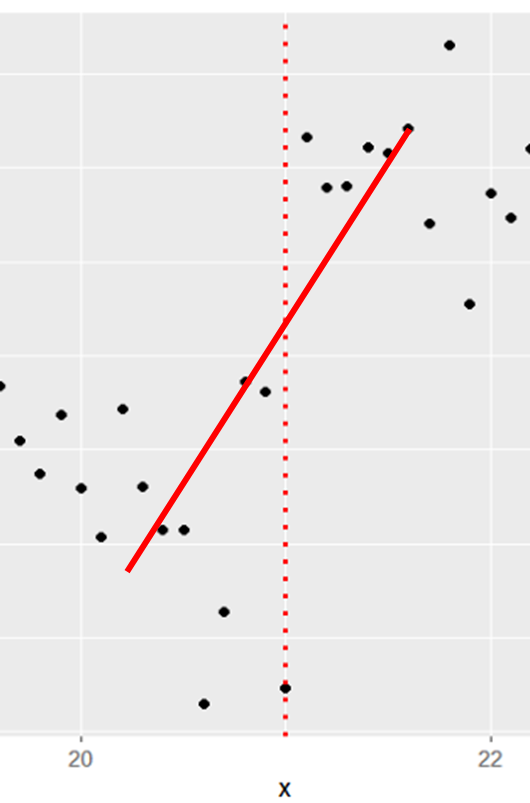
똑같이 선형으로 설명하지만, 왼쪽과 오른쪽은 해석이 정 반대로 될 수 있다.
- 왼쪽 그림은 18 ~ 24까지 구간을 잡았는데, 감소 추세는 21 전후로 똑같이 유지되지만, 21이라는 값 기점으로 급격하게 패턴이 변하는 것을 볼 수 있다.
- 반면 오른쪽 그림은 20 ~ 22까지 구간을 잡았는데, 반대로 이제는 20세 ~ 22세까지 꾸준히 증가하는 추세로도 해석이 가능해 보인다.
40레벨에 오픈되는 컨텐츠의 파급효과를 분석하기 위해,
- 어떤 모형을 가정하고 사용할 것인지,
- 몇 레벨까지를 분석 대상으로 삼아야 할지
를 결정해야 하는데, 어떤 기준을 쓰느냐에 따라 해석이 달라진다면 꽤나 난감해질 것이다.
부가적인 이슈
야심차게 "40레벨 이후, A 컨텐츠가 오픈되면 유저 잔존율이 높아지지 않을까?"라는 가설을 세웠다고 하더라도, 데이터는 40레벨 전후로도 크게 차이가 없게 나올 가능성이 크다.
그러면 A컨텐츠는 그다지 잔존율에 영향을 미치지 않는 컨텐츠로 해석해도 될까?
바로 그렇게 결론을 내버리기에도 어려운 부분이 있다.
1. 40레벨 이후 유저가 게임에 더 몰입하면서 잔존이 좋아질 수도 있지만, 반대로 컨텐츠를 오픈하고 "모든 걸 다 이뤘다" 하면서 게임을 떠나는 청개구리 유저도 있을 수 있다. 실제로는 A 컨텐츠가 게임에 몰입시키는 역할을 하고 있음에도 불구하고, 청개구리 유저가 이를 상쇄하면서 겉으로 보기에는 티가 안 날 수도 있다.
2. 또, 특정값 전후의 유저는 동질적이라는 가정 자체가 잘 만족되지 않는 경우가 많다. 레벨과 잔존율에 영향을 미치는 다른 변수가 있다면, 가령 38레벨 시점에 좋은 아이템을 주는 푸시가 있었다고 하면 38레벨 시점에 잔존율이 높아질 수 있다. 그러면 40레벨에 컨텐츠 오픈이 잔존율에 미치는 영향력이 그다지 눈에 띄지 않을 수도 있다.
영향을 미치는 변수를 다 파악하는 것도, 통제하는 것도 어려운 일이다.
그리고 사실 레벨 자체가 잔존율과 연관성이 많은 변수이다. 만일 초반 구간의 유저가 레벨업을 열심히 하느라 몰입하느라 잔존율이 높은 상태라고 하면, 초반 구간에 보이는 높은 잔존율로 인해 "A 컨텐츠가 잔존율에 미치는 효과"가 잘 안 보일 수도 있다.
그래서 RD는 매력적이지만, 손에 닿기는 어렵다는 게 결론이다. (허무한 결론..)
간단해 보이지만, 사실은 고려해야 할 것이 많은 까다로운 방법이라고 할 수 있겠다.
'Statistics' 카테고리의 다른 글
| 매칭(Matching)을 통한 인과추론 : 개념부터 실습까지 (feat. ChatGPT) (2) | 2024.03.25 |
|---|---|
| 꼬리에 꼬리를 무는 시계열 개념 정리, 정상성부터 공적분까지 (4) | 2024.01.14 |
| 베이즈 통계학을 공부하면 좋은 이유 (1) | 2023.07.29 |
| 인과추론 학습기 - 05. 2SLS와 LATE의 기본 개념 (2) | 2023.06.29 |
| 인과추론 학습기 - 04. 도구변수의 기본 개념 (2) | 2023.05.20 |
오늘은 인과추론 분석 도구 중 하나인 RD(Regression Discontinuity ; 회귀 불연속 설계)에 대한 글을 써 보려고 한다. "회귀 불연속"이라는 단어가 다소 어려워 보이지만, 개념 자체는 가장 직관적이다.
아슬아슬하게 막차를 탄 사람과 막차를 타지 못한 사람을 비교한다면, 이 두 집단은 정말 간발의 차이밖에 나지 않을테니 둘을 비교하면 인과효과를 파악할 수 있다는 뜻이다.
조금 더 구체적으로 예시를 들면 수능 등급을 생각해볼 수 있을 것 같다.
분명 국어(라떼는 언어 영역이었지만..), 수학, 영어 모두 점수는 1점 단위이지만 등급은 1점 차이로 짤없이 갈린다.
만약 96점이 1등급 컷이었다고 하면, 95점이랑 96점은 1점이라는 미미한 차이밖에 나지 않지만,
등급 기준으로는 95점은 2등급, 96점은 1등급에 배정된다.
만일 수능 등급이 인생에 미치는 영향(...은 너무 거시적이고 추상적이지만)을 분석하겠다고 하면, "95점 - 96점 집단을 비교해서 인과 효과를 파악해보겠다!"는 게 바로 회귀 불연속 설계의 개념이라 할 수 있겠다.
본격적으로 RD에 대해 이야기하기 전에 몇 가지 용어에 대해 먼저 이야기하고 넘어가보려 한다.
RD 이해에 필요한 기본 용어
배정 변수(Running Variable)
- 처치 여부를 결정하는 변수로, 수능 등급 컷 예시에서는 점수라고 보면 될 것 같다.
- 수능등급(처치변수)은 오로지 점수에 의해서만 영향을 받는다.
계단형 RD (sharp RD)
- 배정변수가 임계치를 통과한다면 처치가 0% 또는 100%로 완벽하게 결정되는 상황을 의미한다.
- 수능 등급 컷도 계단형 RD인데, 점수에 따라 특정 등급이 100% 결정되기 때문이다.
경사형 RD (fuzzy RD)
- 계단형 RD와 달리 배정변수가 임계치를 통과한다면, 처치 여부가 결정될 확률이 높아지기는 하지만 100%는 아닌 상황을 의미한다.
- 등급 컷 예시는 경사형 RD는 아닌데, 95점인 학생 중 1등급은 30%, 2등급 70%, 96점인 학생 중 1등급 80%, 2등급 20% 이렇게 나오는 경우는 없기 때문이다.
임계치 전후로 처치 여부가 결정되는 상황은 굉장히 매력적이다. 특히 게임에서는 특정 값(예를 들어 레벨) 전후로 상황이 달라지는 경우가 많기 때문에 혹시 RD를 써먹을 수도 있지 않을까? 하는 입맛을 다시게 되는 경우가 많다.
내 레벨에 따라 특정 컨텐츠가 오픈되기도 하고,
내가 진행한 스테이지 레벨에 따라 특정 컨텐츠가 오픈되기도 한다.
혹시 어떤 컨텐츠가 유저로 하여금 게임을 더 열심히 하도록 만드는 동기부여가 될 수 있지 않을까?
그리고 우리는 컨텐츠 개방조건을 아슬아슬하게 만족한 유저와 만족하지 못한 유저를 비교한다면 특정 컨텐츠의 동기 부여 효과를 분석할 수도 있지 않을까?
결론부터 말하면 굉장히 어렵다....
RD 분석 시 주의점
RD를 잘 써먹는다는 건 굉장히 힘든 일이다.
1. 어떤 함수를 쓸 건지(Functional Form)
2. 특정값 전후로 얼만큼의 구간을 사용할 것인지(bandwidth)
를 결정해야 하는데, 이게 생각보다 쉽지 않은 문제다.
이런 데이터를 갖고 있다고 가정해보자.
21 전후로 뭔가 패턴이 달라지는 것 같다는 생각이 든다. 그러면 어떻게 이 패턴을 설명하면 좋을까?
- 왼쪽 그림과 같이 해석하면 21이라는 값이 미치는 파급효과가 꽤 커보인다.
- 하지만 오른쪽 그림과 같이 해석하면 21이라는 값이 뭔가의 자연스러운 흐름으로, 그다지 중요한 값으로 보이지는 않는다.
또 특정값 전후로 구간을 얼마나 잡느냐도 해석이 크게 달라질 수 있는데,
똑같이 선형으로 설명하지만, 왼쪽과 오른쪽은 해석이 정 반대로 될 수 있다.
- 왼쪽 그림은 18 ~ 24까지 구간을 잡았는데, 감소 추세는 21 전후로 똑같이 유지되지만, 21이라는 값 기점으로 급격하게 패턴이 변하는 것을 볼 수 있다.
- 반면 오른쪽 그림은 20 ~ 22까지 구간을 잡았는데, 반대로 이제는 20세 ~ 22세까지 꾸준히 증가하는 추세로도 해석이 가능해 보인다.
40레벨에 오픈되는 컨텐츠의 파급효과를 분석하기 위해,
- 어떤 모형을 가정하고 사용할 것인지,
- 몇 레벨까지를 분석 대상으로 삼아야 할지
를 결정해야 하는데, 어떤 기준을 쓰느냐에 따라 해석이 달라진다면 꽤나 난감해질 것이다.
부가적인 이슈
야심차게 "40레벨 이후, A 컨텐츠가 오픈되면 유저 잔존율이 높아지지 않을까?"라는 가설을 세웠다고 하더라도, 데이터는 40레벨 전후로도 크게 차이가 없게 나올 가능성이 크다.
그러면 A컨텐츠는 그다지 잔존율에 영향을 미치지 않는 컨텐츠로 해석해도 될까?
바로 그렇게 결론을 내버리기에도 어려운 부분이 있다.
1. 40레벨 이후 유저가 게임에 더 몰입하면서 잔존이 좋아질 수도 있지만, 반대로 컨텐츠를 오픈하고 "모든 걸 다 이뤘다" 하면서 게임을 떠나는 청개구리 유저도 있을 수 있다. 실제로는 A 컨텐츠가 게임에 몰입시키는 역할을 하고 있음에도 불구하고, 청개구리 유저가 이를 상쇄하면서 겉으로 보기에는 티가 안 날 수도 있다.
2. 또, 특정값 전후의 유저는 동질적이라는 가정 자체가 잘 만족되지 않는 경우가 많다. 레벨과 잔존율에 영향을 미치는 다른 변수가 있다면, 가령 38레벨 시점에 좋은 아이템을 주는 푸시가 있었다고 하면 38레벨 시점에 잔존율이 높아질 수 있다. 그러면 40레벨에 컨텐츠 오픈이 잔존율에 미치는 영향력이 그다지 눈에 띄지 않을 수도 있다.
영향을 미치는 변수를 다 파악하는 것도, 통제하는 것도 어려운 일이다.
그리고 사실 레벨 자체가 잔존율과 연관성이 많은 변수이다. 만일 초반 구간의 유저가 레벨업을 열심히 하느라 몰입하느라 잔존율이 높은 상태라고 하면, 초반 구간에 보이는 높은 잔존율로 인해 "A 컨텐츠가 잔존율에 미치는 효과"가 잘 안 보일 수도 있다.
그래서 RD는 매력적이지만, 손에 닿기는 어렵다는 게 결론이다. (허무한 결론..)
간단해 보이지만, 사실은 고려해야 할 것이 많은 까다로운 방법이라고 할 수 있겠다.
'Statistics' 카테고리의 다른 글
| 매칭(Matching)을 통한 인과추론 : 개념부터 실습까지 (feat. ChatGPT) (2) | 2024.03.25 |
|---|---|
| 꼬리에 꼬리를 무는 시계열 개념 정리, 정상성부터 공적분까지 (4) | 2024.01.14 |
| 베이즈 통계학을 공부하면 좋은 이유 (1) | 2023.07.29 |
| 인과추론 학습기 - 05. 2SLS와 LATE의 기본 개념 (2) | 2023.06.29 |
| 인과추론 학습기 - 04. 도구변수의 기본 개념 (2) | 2023.05.20 |