
Bigquery의 특징 중 하나는 ARRAY라는 형식을 지원한다는 것이다.
몇 년 전의 나는 ARRAY라는 것이 일반 SQL에는 잘 쓰지 않기 때문에 사용할 일이 없다고 생각했었으나, 그건 천만의 말씀 만만의 콩떡이었다. 현재는 쿼리를 짤 때 굉장히 애용하고 있는 요소라 정리하는 차원에서 글을 써보려고 한다.
Array는 무엇이고, 왜 쓰는가?
사실 Array가 무엇인지, 어떻게 쓰는지에 대해서는 굉장히 정리가 잘 된 글들이 많고,
https://zzsza.github.io/gcp/2020/04/12/bigquery-unnest-array-struct/
BigQuery UNNEST, ARRAY, STRUCT 사용 방법
BigQuery Unnest, Array, Struct 사용 방법에 대해 작성한 글입니다 목차 들어가며 BigQuery ARRAY BigQuery STRUCT BigQuery UNNEST 응용 정리
zzsza.github.io
구글 클라우드에서 자체적으로 제공하는 가이드도 굉장히 잘 되어 있는 편이기도 하다.
https://cloud.google.com/bigquery/docs/reference/standard-sql/arrays?hl=ko
배열 작업 | BigQuery | Google Cloud
의견 보내기 배열 작업 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. BigQuery용 GoogleSQL에서 배열은 데이터 유형이 동일한 0개 이상의 값으로 구성된 순서가
cloud.google.com
Array를 써먹고 있는 사람의 입장에서 몇 가지 의견을 더하는 형태로 글을 써보면
- Array는 Python의 List와 비슷한 개념이다.
- 리스트와 비슷하게 Index 개념이 있다.
정도가 특징인데, 이 특징을 데이터를 세로로 길게 만들어야 하는 상황이 올 때 주로 써먹게 된다.
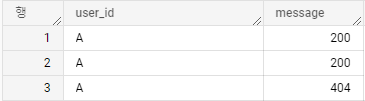
가령,

이런 데이터가 있을 때, 각 메시지가 무엇을 의미하는지 정보를 보여주고 싶을 수 있다.

이 모양으로 데이터를 만들 때, Array 개념으로 접근하면, 매우 쉽게 문제를 해결할 수 있다.
with message_data AS
(
SELECT 'A 'as user_id, 200 AS message_1, 200 AS message_2, 404 AS message_3
)
SELECT
* EXCEPT(message_array)
FROM
(
SELECT
user_id,
array[message_1, message_2, message_3] AS message_array
FROM message_data
),unnest(message_array) AS messagearray로 각 컬럼을 하나의 리스트로 만들고 UNNEST를 통해 풀어버리면 쉽게 가로로 긴 데이터를 세로로 길게 만들 수 있다.
다른 방법을 쓸 수도 있다.
with message_data AS
(
SELECT 'A 'as user_id, 200 AS message_1, 200 AS message_2, 404 AS message_3
)
SELECT
user_id,
message_1
FROM message_data
UNION ALL
(
SELECT
user_id,
message_2
FROM message_data
)
UNION ALL
(
SELECT
user_id,
message_3
FROM message_data
)이렇게 UNION ALL을 써서 데이터를 길게 만드는 방법도 있지만 쿼리가 길어진다는 단점이 있다.
혹은 인덱스 정보가 필요할 때 Array를 사용하기도 하는데 가령

이런 데이터가 있을 때 포켓몬 공격력이 3번째로 높은 데이터를 갖고 오고 싶다고 가정해보자.
여기서는 이상해씨 - 피카츄 - 꼬부기 - 파이리 순으로 공격력이 높기 때문에 꼬부기를 얻어올 수 있으면 된다.
with pokemon_data AS
(
SELECT 1 AS user_id, STRUCT('피카츄' AS pokemon_name, 30 AS attack, 100 AS hp) AS pokemon_info
UNION ALL
SELECT 1 AS user_id, STRUCT('꼬부기' AS pokemon_name, 45 AS attack, 80 AS hp) AS pokemon_info
UNION ALL
SELECT 1 AS user_id, STRUCT('파이리' AS pokemon_name, 55 AS attack, 70 AS hp) AS pokemon_info
UNION ALL
SELECT 1 AS user_id, STRUCT('이상해씨' AS pokemon_name, 20 AS attack, 120 AS hp) AS pokemon_info
)
SELECT
*
FROM
(
SELECT
user_id,
ARRAY_AGG(pokemon_info ORDER BY pokemon_info.attack) AS pokemon_array
FROM pokemon_data
GROUP BY
user_id
),UNNEST(pokemon_array) with offset AS idx
WHERE idx = 2이 때 포켓몬 공격력 순으로 정렬한 형태로 array를 만들고, list에서 인덱스를 알면 특정 데이터를 가져올 수 있는 것처럼 array에서 index를 가져오면 원하는 데이터를 가져올 수 있다.

이렇듯 array를 쓰면 원하는 모양에 맞춰 데이터를 쉽게 조작할 수 있다는 장점이 있다.
이제 데이터를 다시 쪼개고, 모으면서 Array를 쓸 때 알아두면 도움이 될 만한 내용들을 정리하려고 한다. (한 번씩은 내가 삽질을 했던 내용들이다....)
1. SAFE_OFFSET
앞서 array는 리스트와 비슷하기 때문에 원하는 데이터를 인덱싱해서 가져올 수 있다고 했다.
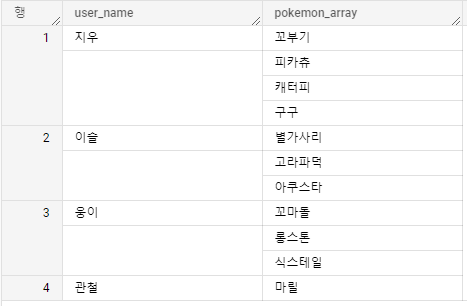
이런 데이터가 있을 때 각 유저(?)마다 두 번째로 잡은 포켓몬을 필터링하고 싶다고 하자.
with pokemon_data AS
(
SELECT '지우' AS user_name, array['꼬부기', '피카츄', '캐터피', '구구'] AS pokemon_array
UNION ALL
SELECT '이슬' AS user_name, array['별가사리', '고라파덕', '아쿠스타']
UNION ALL
SELECT '웅이' AS user_name, array['꼬마돌', '롱스톤', '식스테일']
UNION ALL
SELECT '관철' AS user_name, array['마릴']
)
SELECT
user_name,
pokemon_array[offset(1)] as second_pokomon
FROM pokemon_data
여기서 바로 offset을 쓰면 오류가 난다. 왜냐하면 '관철'은 포켓몬이 1마리이기 때문에 2번째 포켓몬을 가져올 수 없기 때문이다.
처음에는 1마리만 있는 데이터를 버려오는 전략을 썼었다. 즉, array의 길이가 1 초과하는 데이터만 가져오는 것이다. (arary_length 사용)
with pokemon_data AS
(
SELECT '지우' AS user_name, array['꼬부기', '피카츄', '캐터피', '구구'] AS pokemon_array
UNION ALL
SELECT '이슬' AS user_name, array['별가사리', '고라파덕', '아쿠스타']
UNION ALL
SELECT '웅이' AS user_name, array['꼬마돌', '롱스톤', '식스테일']
UNION ALL
SELECT '관철' AS user_name, array['마릴']
)
SELECT
user_name,
pokemon_array[offset(1)] as second_pokomon
FROM pokemon_data
WHERE array_length(pokemon_array) > 1
이렇게 쓰면 데이터를 아래와 같이 가져올 수 있다.
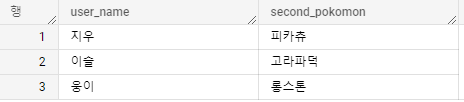
그런데 위 방법을 쓰면 '관철'에 대한 정보를 아예 가져올 수 없게 된다. 포켓몬 2마리가 없어도 데이터를 NULL로 가져오는 식으로 처리를 하고 싶을 수도 있은데 위 방법을 쓰면 데이터를 아예 가져올 수가 없다.
이럴 때, SAFE_OFFSET을 쓰면 되는데,
- 2번째 포켓몬이 있다면, 2번째 포켓몬을 가져오고
- 포켓몬이 1마리만 있다면 2번째 포켓몬을 가져올 수 없는데 이 때 NULL로 표시한다.
with pokemon_data AS
(
SELECT '지우' AS user_name, array['꼬부기', '피카츄', '캐터피', '구구'] AS pokemon_array
UNION ALL
SELECT '이슬' AS usr_name, array['별가사리', '고라파덕', '아쿠스타']
UNION ALL
SELECT '웅이' AS user_name, array['꼬마돌', '롱스톤', '식스테일']
UNION ALL
SELECT '관철' AS user_name, array['마릴']
)
SELECT
user_name,
pokemon_array[safe_offset(1)] as second_pokomon
FROM pokemon_data
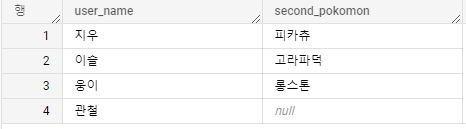
데이터는 이런 모양으로 나오고, 보다 쿼리도 간결해진다.
2. STRING_AGG
사실 이건 Array에 대한 이야기는 아니다. 다만 array에만 함몰되면 못 보는 부분이 있어서, 이 부분에 대해 정리해보려고 한다.
이번에는 array로 묶이지 않은 데이터를 갖고 있다고 해보자. (위의 예시를 UNNEST로 풀면 아래 데이터 형태가 된다.)
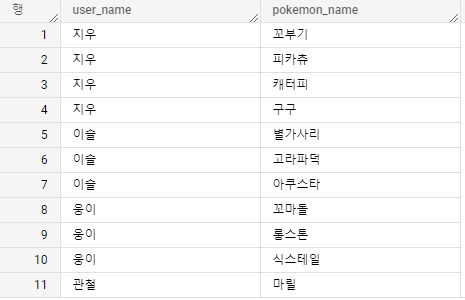
이 데이터를 아래와 같이 갖고 있는 포켓몬을 "-"로 연결하는 한 줄의 데이터를 갖고 싶다고 하자.
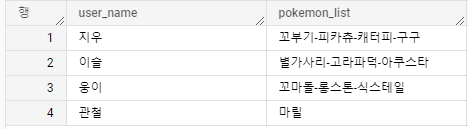
ARRAY_AGG를 써서 문자열을 array로 묶고, 묶은 Array를 array_to_string을 써서 하나의 문자로 만들 수 있다.
with pokemon_data AS
(
SELECT '지우' AS user_name, array['꼬부기', '피카츄', '캐터피', '구구'] AS pokemon_array
UNION ALL
SELECT '이슬' AS user_name, array['별가사리', '고라파덕', '아쿠스타']
UNION ALL
SELECT '웅이' AS user_name, array['꼬마돌', '롱스톤', '식스테일']
UNION ALL
SELECT '관철' AS user_name, array['마릴']
),
pokemon_data_long AS
(
SELECT
* EXCEPT(pokemon_array)
FROM pokemon_data,UNNEST(pokemon_array) AS pokemon_name
)
SELECT
user_name,
ARRAY_TO_STRING(pokemon_array, "-") AS pokemon_list
FROM
(
SELECT
user_name,
ARRAY_AGG(pokemon_name) AS pokemon_array
FROM pokemon_data_long
GROUP BY
user_name
)
그렇지만 문자를 Array로 묶었다 풀었다 하는 모습이 어쩐지 번잡스러워 보인다.
이럴 때 쓰는 게 STRING_AGG인데, 문자열을 원하는 구분자(예시에서는 대시(-))로 묶어서 보여준다.
with pokemon_data AS
(
SELECT '지우' AS user_name, array['꼬부기', '피카츄', '캐터피', '구구'] AS pokemon_array
UNION ALL
SELECT '이슬' AS usr_name, array['별가사리', '고라파덕', '아쿠스타']
UNION ALL
SELECT '웅이' AS user_name, array['꼬마돌', '롱스톤', '식스테일']
UNION ALL
SELECT '관철' AS user_name, array['마릴']
),
pokemon_data_long AS
(
SELECT
* EXCEPT(pokemon_array)
FROM pokemon_data,UNNEST(pokemon_array) AS pokemon_name
)
SELECT
user_name,
STRING_AGG(pokemon_name, "-") AS pokemon_list
FROM pokemon_data_long
GROUP BY
user_name
ARRAY에 현혹되면 모든 걸 다 Array로 처리하고 싶어지는데, 이럴 때 쉽게 가는 길을 돌아서 가게 되는 불상사를 만들어 낼 수 있어 주의해야 한다.
3. ML.NGRAMS
가령, "첫 번째 포켓몬을 물 포켓몬을 선택하면, 유저는 약점을 보완해주기 위해 두 번째 포켓몬으로 구구(비행 속성)를 잡는 경향이 있을 것이다" 라는 가설을 세웠다고 가정해보자.
(참고로 물 포켓몬은 풀 포켓몬에 약하고, 비행 포켓몬은 풀 포켓몬에 강하다)
그리고 나는 이런 데이터를 가지고 있다고 해보자.
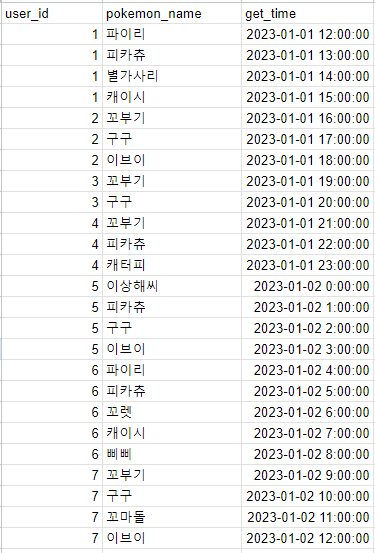
이 때 내가 원하는 데이터는
유저가 잡은 첫번째 포켓몬 - 유저가 잡은 두번째 포켓몬 - 유저 수에 대한 정보이다.
이런 데이터 형태를 만들기 위해서는 다양한 방법을 사용할 수 있겠으나, 첫번째 - 두번째 포켓몬의 조합을 만들어서 처리하면 간단하게 처리할 수 있을 것 같다는 생각이 든다.
다른 SQL에도 지원하는 기능인지는 모르겠지만, bigquery에는 조합(Combination)을 만들어주는 ML.NGLAMS 라는 함수가 있다.
해당 함수에 Array를 넣어주고, 몇 개의 조합을 만들고 싶은지, 그리고 구분자로 어떤 걸 넣어주고 싶은지를 parameter로 넣어주면 된다!
with org_data AS
(
SELECT
*
FROM `get_pokemon_log`
),
array_data AS
(
SELECT
user_id,
ARRAY_AGG(pokemon_name ORDER BY get_time) AS pokemon_array
FROM
(
SELECT
*,
ROW_NUMBER() OVER (partition by user_id ORDER BY get_time) AS idx
FROM org_data
)
GROUP BY
user_id
) SELECT
* EXCEPT(pokemon_array),
ML.NGRAMS(pokemon_array, [1, 3], "-")
FROM array_data맨 아래줄 쿼리 중 ML.NGRAMS가 조합을 만들어주는 함수 부분이고, [1, 3]이라고 쓰인 부분은 조합을 1개 ~ 3개까지 만들어 달라는 뜻이다.
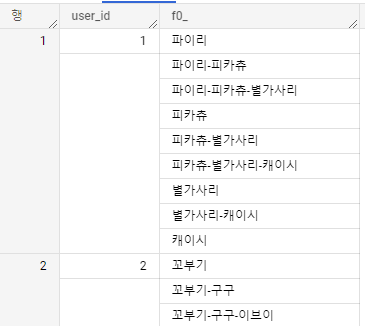
그러면 이런 식으로 1~3개 사이의 조합을 만들어준다.
그럼 위 명령어를 사용해서, 첫번째 - 두번째 포켓몬의 조합을 만들어보자.
with org_data AS
(
SELECT
*
FROM `get_pokemon_log`
),
array_data AS
(
SELECT
user_id,
ARRAY_AGG(pokemon_name ORDER BY get_time) AS pokemon_array
FROM
(
SELECT
*,
ROW_NUMBER() OVER (partition by user_id ORDER BY get_time) AS idx
FROM org_data
)
WHERE idx <= 2
GROUP BY
user_id
),
combination_data AS
(
SELECT
*
FROM array_data, UNNEST(ML.NGRAMS(pokemon_array, [2], "-")) AS pokemon_tuple
)
SELECT
SPLIT(pokemon_tuple, "-")[SAFE_OFFSET(0)] AS pokemon_1,
SPLIT(pokemon_tuple, "-")[SAFE_OFFSET(1)] AS pokemon_2,
COUNT(1) AS get_cnt
FROM combination_data
GROUP BY
pokemon_1,
pokemon_2
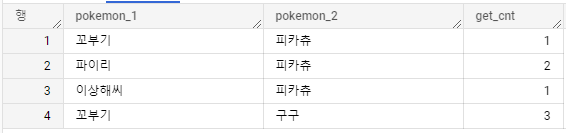
그러면 위와 같은 결과를 얻을 수 있다.
사실 의도적으로 조작(?)해서 만든 데이터긴 하지만... 꼬부기를 잡은 경우 두번째 포켓몬으로 유저는 구구를 선택하고 그렇지 않은 경우(파이리, 이상해씨)는 피카츄를 데려가는 경향이 있는 것을 확인할 수 있다.
Array는 잘 써먹기만 하면 데이터 분석을 쉽게 만들어주기 때문에 유용한 도구라고 말할 수 있겠다.

Array를 통해 진짜로 골치아픈 일을 해치워버릴 수 있으면 하는 바람으로 글을 마쳐본다.
'Tools > SQL' 카테고리의 다른 글
| 데이터 분석가의 야매 빅쿼리(BigQuery) 쿼리 최적화 (0) | 2025.02.28 |
|---|
Bigquery의 특징 중 하나는 ARRAY라는 형식을 지원한다는 것이다.
몇 년 전의 나는 ARRAY라는 것이 일반 SQL에는 잘 쓰지 않기 때문에 사용할 일이 없다고 생각했었으나, 그건 천만의 말씀 만만의 콩떡이었다. 현재는 쿼리를 짤 때 굉장히 애용하고 있는 요소라 정리하는 차원에서 글을 써보려고 한다.
Array는 무엇이고, 왜 쓰는가?
사실 Array가 무엇인지, 어떻게 쓰는지에 대해서는 굉장히 정리가 잘 된 글들이 많고,
https://zzsza.github.io/gcp/2020/04/12/bigquery-unnest-array-struct/
BigQuery UNNEST, ARRAY, STRUCT 사용 방법
BigQuery Unnest, Array, Struct 사용 방법에 대해 작성한 글입니다 목차 들어가며 BigQuery ARRAY BigQuery STRUCT BigQuery UNNEST 응용 정리
zzsza.github.io
구글 클라우드에서 자체적으로 제공하는 가이드도 굉장히 잘 되어 있는 편이기도 하다.
https://cloud.google.com/bigquery/docs/reference/standard-sql/arrays?hl=ko
배열 작업 | BigQuery | Google Cloud
의견 보내기 배열 작업 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. BigQuery용 GoogleSQL에서 배열은 데이터 유형이 동일한 0개 이상의 값으로 구성된 순서가
cloud.google.com
Array를 써먹고 있는 사람의 입장에서 몇 가지 의견을 더하는 형태로 글을 써보면
- Array는 Python의 List와 비슷한 개념이다.
- 리스트와 비슷하게 Index 개념이 있다.
정도가 특징인데, 이 특징을 데이터를 세로로 길게 만들어야 하는 상황이 올 때 주로 써먹게 된다.
가령,
이런 데이터가 있을 때, 각 메시지가 무엇을 의미하는지 정보를 보여주고 싶을 수 있다.
이 모양으로 데이터를 만들 때, Array 개념으로 접근하면, 매우 쉽게 문제를 해결할 수 있다.
with message_data AS
(
SELECT 'A 'as user_id, 200 AS message_1, 200 AS message_2, 404 AS message_3
)
SELECT
* EXCEPT(message_array)
FROM
(
SELECT
user_id,
array[message_1, message_2, message_3] AS message_array
FROM message_data
),unnest(message_array) AS messagearray로 각 컬럼을 하나의 리스트로 만들고 UNNEST를 통해 풀어버리면 쉽게 가로로 긴 데이터를 세로로 길게 만들 수 있다.
다른 방법을 쓸 수도 있다.
with message_data AS
(
SELECT 'A 'as user_id, 200 AS message_1, 200 AS message_2, 404 AS message_3
)
SELECT
user_id,
message_1
FROM message_data
UNION ALL
(
SELECT
user_id,
message_2
FROM message_data
)
UNION ALL
(
SELECT
user_id,
message_3
FROM message_data
)이렇게 UNION ALL을 써서 데이터를 길게 만드는 방법도 있지만 쿼리가 길어진다는 단점이 있다.
혹은 인덱스 정보가 필요할 때 Array를 사용하기도 하는데 가령
이런 데이터가 있을 때 포켓몬 공격력이 3번째로 높은 데이터를 갖고 오고 싶다고 가정해보자.
여기서는 이상해씨 - 피카츄 - 꼬부기 - 파이리 순으로 공격력이 높기 때문에 꼬부기를 얻어올 수 있으면 된다.
with pokemon_data AS
(
SELECT 1 AS user_id, STRUCT('피카츄' AS pokemon_name, 30 AS attack, 100 AS hp) AS pokemon_info
UNION ALL
SELECT 1 AS user_id, STRUCT('꼬부기' AS pokemon_name, 45 AS attack, 80 AS hp) AS pokemon_info
UNION ALL
SELECT 1 AS user_id, STRUCT('파이리' AS pokemon_name, 55 AS attack, 70 AS hp) AS pokemon_info
UNION ALL
SELECT 1 AS user_id, STRUCT('이상해씨' AS pokemon_name, 20 AS attack, 120 AS hp) AS pokemon_info
)
SELECT
*
FROM
(
SELECT
user_id,
ARRAY_AGG(pokemon_info ORDER BY pokemon_info.attack) AS pokemon_array
FROM pokemon_data
GROUP BY
user_id
),UNNEST(pokemon_array) with offset AS idx
WHERE idx = 2이 때 포켓몬 공격력 순으로 정렬한 형태로 array를 만들고, list에서 인덱스를 알면 특정 데이터를 가져올 수 있는 것처럼 array에서 index를 가져오면 원하는 데이터를 가져올 수 있다.
이렇듯 array를 쓰면 원하는 모양에 맞춰 데이터를 쉽게 조작할 수 있다는 장점이 있다.
이제 데이터를 다시 쪼개고, 모으면서 Array를 쓸 때 알아두면 도움이 될 만한 내용들을 정리하려고 한다. (한 번씩은 내가 삽질을 했던 내용들이다....)
1. SAFE_OFFSET
앞서 array는 리스트와 비슷하기 때문에 원하는 데이터를 인덱싱해서 가져올 수 있다고 했다.
이런 데이터가 있을 때 각 유저(?)마다 두 번째로 잡은 포켓몬을 필터링하고 싶다고 하자.
with pokemon_data AS
(
SELECT '지우' AS user_name, array['꼬부기', '피카츄', '캐터피', '구구'] AS pokemon_array
UNION ALL
SELECT '이슬' AS user_name, array['별가사리', '고라파덕', '아쿠스타']
UNION ALL
SELECT '웅이' AS user_name, array['꼬마돌', '롱스톤', '식스테일']
UNION ALL
SELECT '관철' AS user_name, array['마릴']
)
SELECT
user_name,
pokemon_array[offset(1)] as second_pokomon
FROM pokemon_data
여기서 바로 offset을 쓰면 오류가 난다. 왜냐하면 '관철'은 포켓몬이 1마리이기 때문에 2번째 포켓몬을 가져올 수 없기 때문이다.
처음에는 1마리만 있는 데이터를 버려오는 전략을 썼었다. 즉, array의 길이가 1 초과하는 데이터만 가져오는 것이다. (arary_length 사용)
with pokemon_data AS
(
SELECT '지우' AS user_name, array['꼬부기', '피카츄', '캐터피', '구구'] AS pokemon_array
UNION ALL
SELECT '이슬' AS user_name, array['별가사리', '고라파덕', '아쿠스타']
UNION ALL
SELECT '웅이' AS user_name, array['꼬마돌', '롱스톤', '식스테일']
UNION ALL
SELECT '관철' AS user_name, array['마릴']
)
SELECT
user_name,
pokemon_array[offset(1)] as second_pokomon
FROM pokemon_data
WHERE array_length(pokemon_array) > 1
이렇게 쓰면 데이터를 아래와 같이 가져올 수 있다.
그런데 위 방법을 쓰면 '관철'에 대한 정보를 아예 가져올 수 없게 된다. 포켓몬 2마리가 없어도 데이터를 NULL로 가져오는 식으로 처리를 하고 싶을 수도 있은데 위 방법을 쓰면 데이터를 아예 가져올 수가 없다.
이럴 때, SAFE_OFFSET을 쓰면 되는데,
- 2번째 포켓몬이 있다면, 2번째 포켓몬을 가져오고
- 포켓몬이 1마리만 있다면 2번째 포켓몬을 가져올 수 없는데 이 때 NULL로 표시한다.
with pokemon_data AS
(
SELECT '지우' AS user_name, array['꼬부기', '피카츄', '캐터피', '구구'] AS pokemon_array
UNION ALL
SELECT '이슬' AS usr_name, array['별가사리', '고라파덕', '아쿠스타']
UNION ALL
SELECT '웅이' AS user_name, array['꼬마돌', '롱스톤', '식스테일']
UNION ALL
SELECT '관철' AS user_name, array['마릴']
)
SELECT
user_name,
pokemon_array[safe_offset(1)] as second_pokomon
FROM pokemon_data
데이터는 이런 모양으로 나오고, 보다 쿼리도 간결해진다.
2. STRING_AGG
사실 이건 Array에 대한 이야기는 아니다. 다만 array에만 함몰되면 못 보는 부분이 있어서, 이 부분에 대해 정리해보려고 한다.
이번에는 array로 묶이지 않은 데이터를 갖고 있다고 해보자. (위의 예시를 UNNEST로 풀면 아래 데이터 형태가 된다.)
이 데이터를 아래와 같이 갖고 있는 포켓몬을 "-"로 연결하는 한 줄의 데이터를 갖고 싶다고 하자.
ARRAY_AGG를 써서 문자열을 array로 묶고, 묶은 Array를 array_to_string을 써서 하나의 문자로 만들 수 있다.
with pokemon_data AS
(
SELECT '지우' AS user_name, array['꼬부기', '피카츄', '캐터피', '구구'] AS pokemon_array
UNION ALL
SELECT '이슬' AS user_name, array['별가사리', '고라파덕', '아쿠스타']
UNION ALL
SELECT '웅이' AS user_name, array['꼬마돌', '롱스톤', '식스테일']
UNION ALL
SELECT '관철' AS user_name, array['마릴']
),
pokemon_data_long AS
(
SELECT
* EXCEPT(pokemon_array)
FROM pokemon_data,UNNEST(pokemon_array) AS pokemon_name
)
SELECT
user_name,
ARRAY_TO_STRING(pokemon_array, "-") AS pokemon_list
FROM
(
SELECT
user_name,
ARRAY_AGG(pokemon_name) AS pokemon_array
FROM pokemon_data_long
GROUP BY
user_name
)
그렇지만 문자를 Array로 묶었다 풀었다 하는 모습이 어쩐지 번잡스러워 보인다.
이럴 때 쓰는 게 STRING_AGG인데, 문자열을 원하는 구분자(예시에서는 대시(-))로 묶어서 보여준다.
with pokemon_data AS
(
SELECT '지우' AS user_name, array['꼬부기', '피카츄', '캐터피', '구구'] AS pokemon_array
UNION ALL
SELECT '이슬' AS usr_name, array['별가사리', '고라파덕', '아쿠스타']
UNION ALL
SELECT '웅이' AS user_name, array['꼬마돌', '롱스톤', '식스테일']
UNION ALL
SELECT '관철' AS user_name, array['마릴']
),
pokemon_data_long AS
(
SELECT
* EXCEPT(pokemon_array)
FROM pokemon_data,UNNEST(pokemon_array) AS pokemon_name
)
SELECT
user_name,
STRING_AGG(pokemon_name, "-") AS pokemon_list
FROM pokemon_data_long
GROUP BY
user_name
ARRAY에 현혹되면 모든 걸 다 Array로 처리하고 싶어지는데, 이럴 때 쉽게 가는 길을 돌아서 가게 되는 불상사를 만들어 낼 수 있어 주의해야 한다.
3. ML.NGRAMS
가령, "첫 번째 포켓몬을 물 포켓몬을 선택하면, 유저는 약점을 보완해주기 위해 두 번째 포켓몬으로 구구(비행 속성)를 잡는 경향이 있을 것이다" 라는 가설을 세웠다고 가정해보자.
(참고로 물 포켓몬은 풀 포켓몬에 약하고, 비행 포켓몬은 풀 포켓몬에 강하다)
그리고 나는 이런 데이터를 가지고 있다고 해보자.
이 때 내가 원하는 데이터는
유저가 잡은 첫번째 포켓몬 - 유저가 잡은 두번째 포켓몬 - 유저 수에 대한 정보이다.
이런 데이터 형태를 만들기 위해서는 다양한 방법을 사용할 수 있겠으나, 첫번째 - 두번째 포켓몬의 조합을 만들어서 처리하면 간단하게 처리할 수 있을 것 같다는 생각이 든다.
다른 SQL에도 지원하는 기능인지는 모르겠지만, bigquery에는 조합(Combination)을 만들어주는 ML.NGLAMS 라는 함수가 있다.
해당 함수에 Array를 넣어주고, 몇 개의 조합을 만들고 싶은지, 그리고 구분자로 어떤 걸 넣어주고 싶은지를 parameter로 넣어주면 된다!
with org_data AS
(
SELECT
*
FROM `get_pokemon_log`
),
array_data AS
(
SELECT
user_id,
ARRAY_AGG(pokemon_name ORDER BY get_time) AS pokemon_array
FROM
(
SELECT
*,
ROW_NUMBER() OVER (partition by user_id ORDER BY get_time) AS idx
FROM org_data
)
GROUP BY
user_id
) SELECT
* EXCEPT(pokemon_array),
ML.NGRAMS(pokemon_array, [1, 3], "-")
FROM array_data맨 아래줄 쿼리 중 ML.NGRAMS가 조합을 만들어주는 함수 부분이고, [1, 3]이라고 쓰인 부분은 조합을 1개 ~ 3개까지 만들어 달라는 뜻이다.
그러면 이런 식으로 1~3개 사이의 조합을 만들어준다.
그럼 위 명령어를 사용해서, 첫번째 - 두번째 포켓몬의 조합을 만들어보자.
with org_data AS
(
SELECT
*
FROM `get_pokemon_log`
),
array_data AS
(
SELECT
user_id,
ARRAY_AGG(pokemon_name ORDER BY get_time) AS pokemon_array
FROM
(
SELECT
*,
ROW_NUMBER() OVER (partition by user_id ORDER BY get_time) AS idx
FROM org_data
)
WHERE idx <= 2
GROUP BY
user_id
),
combination_data AS
(
SELECT
*
FROM array_data, UNNEST(ML.NGRAMS(pokemon_array, [2], "-")) AS pokemon_tuple
)
SELECT
SPLIT(pokemon_tuple, "-")[SAFE_OFFSET(0)] AS pokemon_1,
SPLIT(pokemon_tuple, "-")[SAFE_OFFSET(1)] AS pokemon_2,
COUNT(1) AS get_cnt
FROM combination_data
GROUP BY
pokemon_1,
pokemon_2
그러면 위와 같은 결과를 얻을 수 있다.
사실 의도적으로 조작(?)해서 만든 데이터긴 하지만... 꼬부기를 잡은 경우 두번째 포켓몬으로 유저는 구구를 선택하고 그렇지 않은 경우(파이리, 이상해씨)는 피카츄를 데려가는 경향이 있는 것을 확인할 수 있다.
Array는 잘 써먹기만 하면 데이터 분석을 쉽게 만들어주기 때문에 유용한 도구라고 말할 수 있겠다.
Array를 통해 진짜로 골치아픈 일을 해치워버릴 수 있으면 하는 바람으로 글을 마쳐본다.
'Tools > SQL' 카테고리의 다른 글
| 데이터 분석가의 야매 빅쿼리(BigQuery) 쿼리 최적화 (0) | 2025.02.28 |
|---|