
지난번에 이어 매번 쓰지만 매번 쓸 때마다 헷갈리는 ggplot 사용법에 대해 정리해두려고 한다.
https://blessedby-clt.tistory.com/28
맨날 헷갈리는 ggplot 시각화 정리(1)
R 원툴이라 ggplot2 패키지를 사용할 일이 많은데도 불구하고, 매번 비슷비슷한 걸로 헷갈려서 한 번 정리 해보는 시간을 가져보기로 했다. 패키지 사용법을 정리하기 전에, 먼저 간단하게 준비물
blessedby-clt.tistory.com
지난번에 쓴 글만 봐도 기본적인 그래프를 그리는 데 문제는 없지만, 축을 변경한다거나 제목을 단다거나 하는 그래프 부가적인 요소는 처리할 수 없다. 하지만 실질적으로 그래프를 쓸 때마다 헷갈리는 건 사소하지만 사소하지 않은, 이런 디자인과 관련된 부분이기에 이번에는 이런 소소한 디자인에 대해 글을 써보려고 한다.
1. 제목 달기
ggplot(data = titanic, aes(x= Sex, y = Freq, fill = Survived)) +
geom_bar(stat = "identity", position = "dodge") +
labs(title = "성별에 따른 생존자") ## labs 함수를 사용해서 표 제목을 달 수 있다.
만약 그래프에 제목을 달고 싶으면, labs 함수의 title 옵션을 써서 제목을 붙일 수 있다.
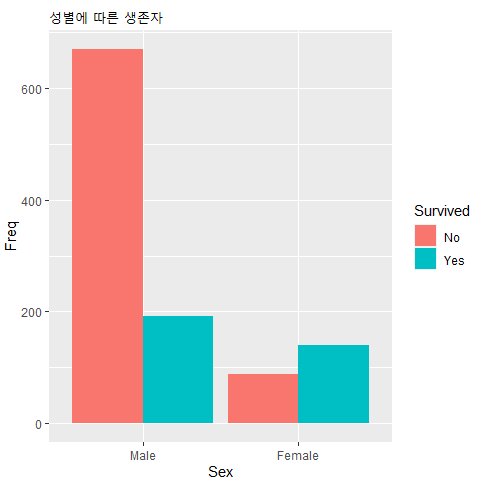
"성별에 따른 생존자"로 그래프 제목을 달았지만, 제목 치고 글씨가 너무 작고 강조가 되어 있지 않아 제목을 알아보기에 어렵다.
그래서 제목 글씨를 키우고, 가운데 정렬을 해서 그래프 제목이 제목답게 보이도록 만들어주자.
theme 옵션을 써서 그래프 부가적인 요소에 대한 옵션을 지정해줄 수 있다.
theme 옵션에 대해서는 line, rect, text 등 다양한 것들을 지정해줄 수 있지만, 제목과 관련된 옵션은 plot.title이므로 이것만 건드려보려고 한다. 각각 옵션에 대한 자세한 활용 방법은 아래 링크에서 확인 가능하다.
https://ggplot2.tidyverse.org/reference/theme.html
Modify components of a theme — theme
Themes are a powerful way to customize the non-data components of your plots: i.e. titles, labels, fonts, background, gridlines, and legends. Themes can be used to give plots a consistent customized look. Modify a single plot's theme using theme(); see the
ggplot2.tidyverse.org
ggplot(data = titanic, aes(x= Sex, y = Freq, fill = Survived)) +
geom_bar(stat = "identity", position = "fill") +
labs(title = "성별에 따른 생존자") +
theme(plot.title = element_text(size = 20, face = "bold", hjust = 0.5)) ## 제목 옵션
플롯의 타이틀(제목)에 들어가는 text(글자)를 건드리려고 한다. size(글자크기), face(굵게, 이텔릭 등등 폰트 옵션), hjust(정렬) 등을 지정해주었다.
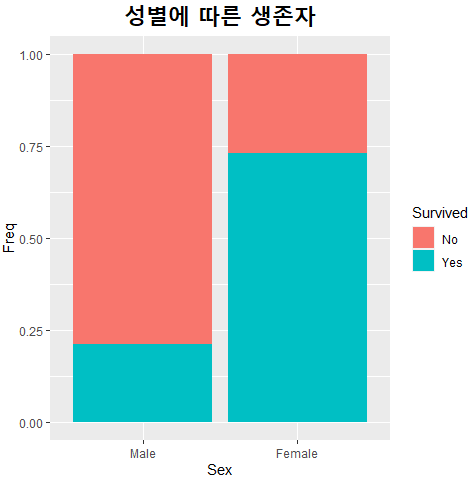
좀 더 제목이 제목다워졌다. (중간에 그래프 형태도 바꾼 건 덤..)
2. 축 옵션
그래프를 그리다보면, x축에 들어가는 정보량이 많아서 그래프가 가시적으로 보이지 않을 때가 있다.
성별에 따른 생존자 그래프에서는 남/녀 두 개 항목만 들어가서 문제가 없지만, 아래 그래프 형태라면 내용 파악에 문제가 될 수 있다.
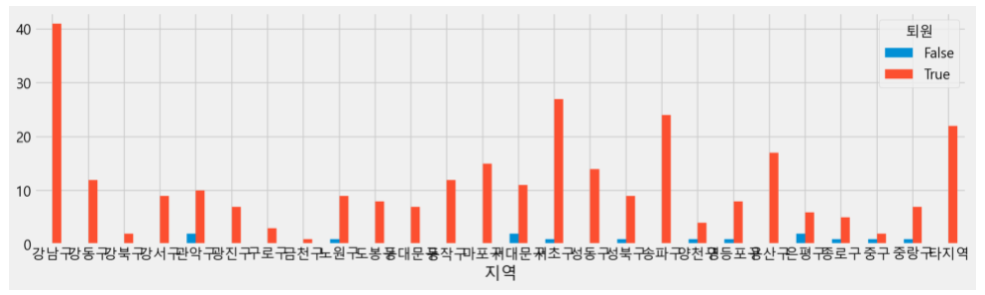
각 구끼리 글씨가 겹쳐서 알아보기 힘들다. 물론 자신이 서울시민이다, 하면 무리없이 알아볼 수는 있겠지만 디자인적으로도 예쁘지는 않다. 만약 구 정보가 가로가 아니라 세로로 쓰여있다면, 구 정보를 알아보기 편할 것 같다.
위 그래프로 디자인 옵션을 적용하면 알아보기에 편하겠지만, 저 그래프는 파이썬으로 그린 거라 디자인 옵션을 바꾸는 건 기존의 타이타닉, mtcars 데이터로 대체해서 사용한다 🤦♀️
(1) 축 각도 바꾸기
ggplot(data = titanic, aes(x= Sex, y = Freq, fill = Survived)) +
geom_bar(stat = "identity", position = "fill") +
labs(title = "성별에 따른 생존자") +
theme(plot.title = element_text(size = 20, face = "bold", hjust = 0.5)) +
theme(axis.text.x=element_text(angle=90))
마찬가지로 theme 함수를 사용할 수 있다. 이 경우 axis.text.x > angle 옵션을 사용할 수 있다. 말 그대로 각도를 조정하는 옵션이라 90도로 지정해주면 x축의 글씨를 세로로 바꾸어줄 수 있다.
이 경우 항목이 남/녀 두 개로 2가지 뿐이라 오히려 세로쓰기를 하면서 가독성이 떨어졌다. x축에 항목이 많지 않은 경우에는 가로쓰기를 유지하는 것이 가독성에 더 좋을 수 있다.
(2) x축과 y축을 바꾸기
x축에 항목이 많아 항목 식별이 어렵다면 그래프의 x축과 y축을 바꾸는 방법도 쓸 수 있다. x축과 y축을 바꾸는 옵션은 심미성을 위해서도 사용할 수 있지만, 데이터를 보여주는 분석가의 의도를 강하게 반영할 수 있기 때문에 중요하다.
ggplot(data = titanic, aes(x= Sex, y = Freq, fill = Survived)) +
geom_bar(stat = "identity", position = "fill") +
labs(title = "성별에 따른 생존자") +
theme(plot.title = element_text(size = 20, face = "bold")) +
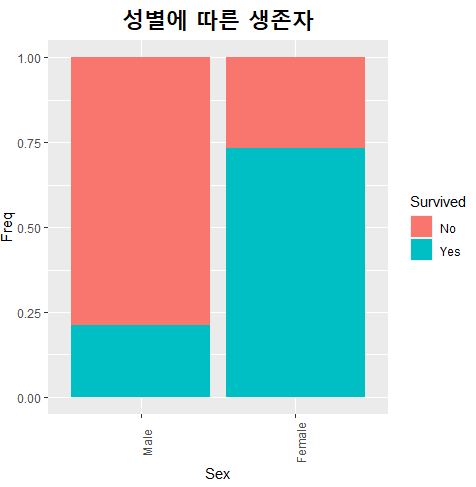
theme(axis.text.x=element_text(angle=90,hjust=1)) +
coord_flip() ## 이거 하나면 x축과 y축을 바꿀 수 있다.
방법 자체는 간단하다. coord_flip 이거 하나만 입력하면 아래와 같이 x축에 비율이, y축에 성별이 들어가게 된다.
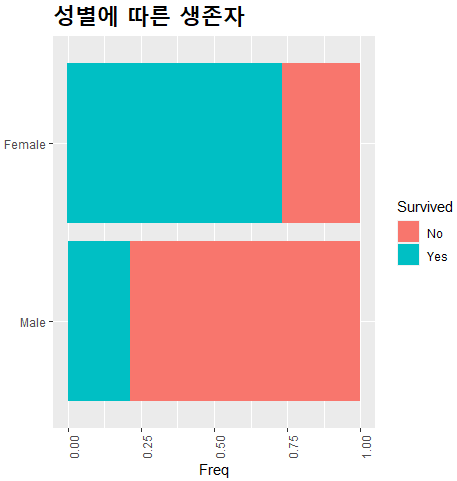
(1) 축 각도 바꾸기 에서는 x축의 항목이 남/녀 둘 뿐이라 사실은 의미가 없는 작업이라고 했는데,
(2) x축과 y축을 바꾸기 에서는 나름 유의미한 부분이 있다.
x축에 성별 / y축에 비율이 있을 때는 남자의 생존율이 "25%", 여자의 생존율이 "75%"네, 수치를 강조할 수 있지만
반대로 x축에 비율 / y축에 성별이 있는 경우에는 남/녀 생존율이 "엄청나게 차이나네"를 강조할 수 있다.
또 세로 막대 그래프인 경우에는 (x축을 자세히 보지 않는다면) 시간의 흐름에 따른 데이터인지, 혹은 항목을 비교하는 데이터인지 헷갈릴 우려가 있지만 가로 막대 그래프를 그릴 경우에는 그럴 우려가 현저히 줄어든다.
(3) 축 범위 조정하기
범위 옵션을 지정하지 않는 경우에도 자동적으로 그래프를 그려준다.
- 그렇지만 가령 데이터에 이상치가 있어 그 이상치 때문에 전반적인 추세가 보이지 않는 경우, 내가 원하는 범위만큼만 지정해서 그래프를 그려줄 필요가 있고,
- 혹은 특정 구간이 중요한 경우, 예를 들어 시험점수는 반드시 10점 단위로 끊어서 봐야 하는데, 그래프는 20점 단위로 끊어서 그려줬다고 하면 내가 임의로 10점 단위로 끊어서 그래프를 그려야 한다.
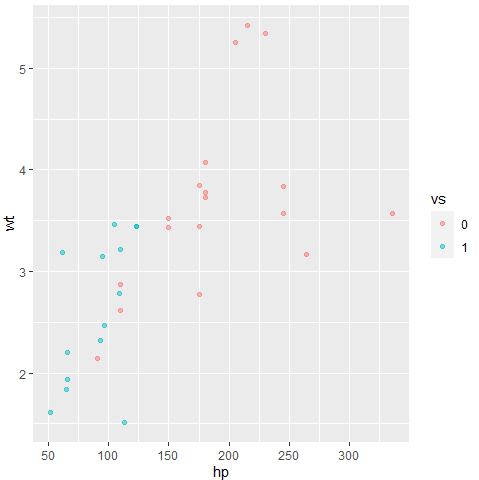
ggplot(data = mtcars, aes(x= hp, y = wt, color = vs)) +
geom_point(alpha = 0.5)+
scale_x_continuous(breaks = seq(0, 400, 50))
이 때는 scale_x_continuous 함수를 사용할 수 있다. (x축이 연속형 변수라 continuous)
seq 함수에서 (시작점, 끝점, 구간) 이렇게 값을 지정해주면 내가 원하는 모양으로 축 범위를 잡아서 그래프를 그려준다.
3. 레이블 달기
필요한 경우 데이터에 값 레이블을 붙여야 할 때가 있다. 만일 산점도나 선 그래프에 값 레이블을 붙여야 할 경우 ggrepel 패키지를 사용하면 레이블을 꽤나 깔끔하게 붙여준다.
ggplot(data = mtcars, aes(x= hp, y = wt, color = vs)) +
geom_point(alpha = 0.5)+
scale_x_continuous(breaks = seq(0, 400, 50)) +
ggrepel::geom_text_repel(aes(label = wt, size = 0.4))
geom_text_repel 함수에 label(어떤 값을 레이블로 붙일 것인지), size(크기는 어느정도?) 옵션을 지정해주었다.
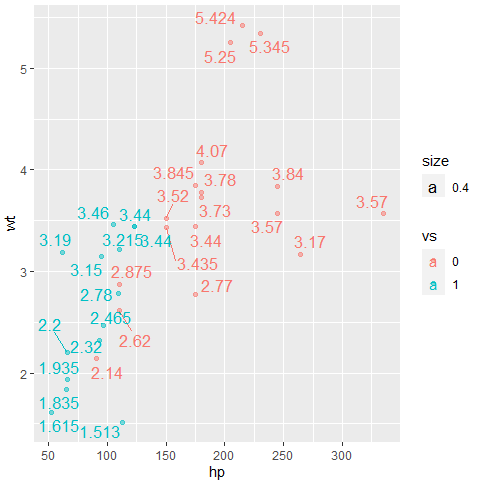
그러면 아래와 같이 그래프를 그려주는데 값이 겹쳐서 보기 어려운 경우에는 선을 길게 빼서, 값을 보기 편하게 자동적으로 만들어준다.
4. 여러 데이터를 동시에 보여줄 때
데이터 변수 간의 관계성을 알고 싶을 때, ggpairs 함수를 쓰면 한 번에 간단하게 그래프를 그려준다.
library(GGally)
ggpairs(mtcars)
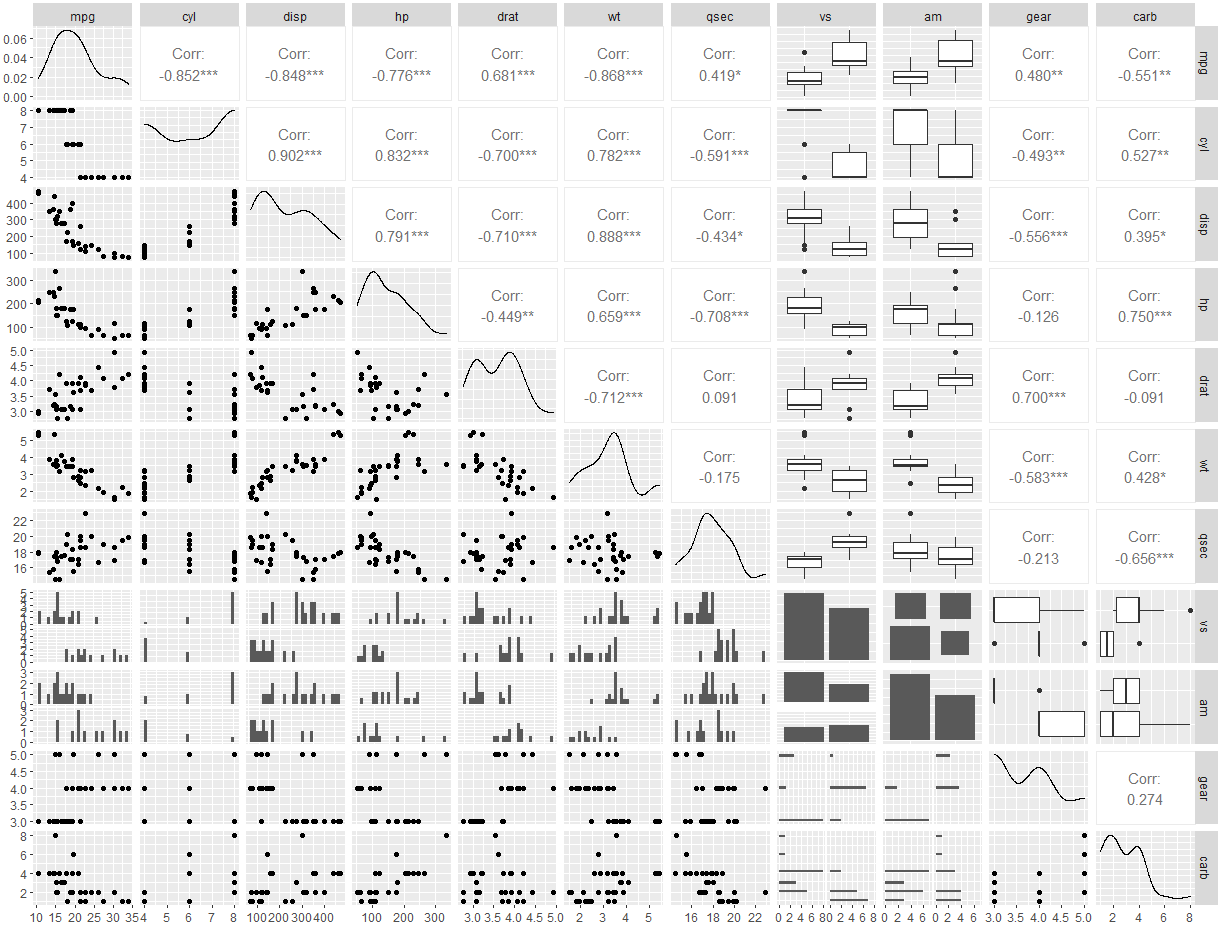
연속형 변수 vs 연속형 변수인 경우에는 산점도도 그려주고,
범주형 변수 vs 연속형 변수인 경우에는 boxplot도 그려주고, 나름대로 correlation도 계산해주는 굉장히 편리하고 좋은 라이브러리이지만..
적은 양의 데이터도 그래프를 그려주는데 시간이 오래 걸리고, 데이터의 양이 많을 경우에는 R이 뻗어버리는 경우가 왕왕 있어 이름 뿐인 필살기인 경우가 될 경우가 많다는 게 단점이다.
그래서 실질적으로 ggpair을 사용하지는 않고,(이런 필살기가 있다는 것만 알아두는 수준)
변수 별로 데이터 분포를 확인하고 싶을 때는 dplyr의 chain 함수와 ggplot을 결합하여 사용하거나
변수 간 산점도를 보고 싶을 때는 함수를 만들어 사용하는 편이다.
g = ggplot(data = select_if(mtcars, is.numeric) %>% pivot_longer(cols = everything()))
g + geom_histogram(aes(x = value, fill = name), bins = 10) + facet_wrap(~name, scales = "free_x")
mtcars 데이터에서 is.numeric = True, 즉 연속형 변수인 것만 골라내서 데이터를 세로로 길게 만들어준다.
value에는 값이, name에는 변수명이 들어가도록 만들어서 히스토그램을 그리는 트릭이다.
산점도를 여러 번 반복해서 그리는 것이 불편할 경우에는 함수를 만들어주기도 하는데, 한 번 함수를 만들면 원하는 변수만 넣어서 바로바로 산점도를 그릴 수 있어 편리하다.
make_dotgraph <- function(x, y){
ggplot(data = mtcars, aes(x = .data[[x]], y = .data[[y]])) + geom_point()
}
make_dotgraph("hp", "carb")
지난번에 이어 매번 쓰지만 매번 쓸 때마다 헷갈리는 ggplot 사용법에 대해 정리해두려고 한다.
https://blessedby-clt.tistory.com/28
맨날 헷갈리는 ggplot 시각화 정리(1)
R 원툴이라 ggplot2 패키지를 사용할 일이 많은데도 불구하고, 매번 비슷비슷한 걸로 헷갈려서 한 번 정리 해보는 시간을 가져보기로 했다. 패키지 사용법을 정리하기 전에, 먼저 간단하게 준비물
blessedby-clt.tistory.com
지난번에 쓴 글만 봐도 기본적인 그래프를 그리는 데 문제는 없지만, 축을 변경한다거나 제목을 단다거나 하는 그래프 부가적인 요소는 처리할 수 없다. 하지만 실질적으로 그래프를 쓸 때마다 헷갈리는 건 사소하지만 사소하지 않은, 이런 디자인과 관련된 부분이기에 이번에는 이런 소소한 디자인에 대해 글을 써보려고 한다.
1. 제목 달기
ggplot(data = titanic, aes(x= Sex, y = Freq, fill = Survived)) +
geom_bar(stat = "identity", position = "dodge") +
labs(title = "성별에 따른 생존자") ## labs 함수를 사용해서 표 제목을 달 수 있다.
만약 그래프에 제목을 달고 싶으면, labs 함수의 title 옵션을 써서 제목을 붙일 수 있다.
"성별에 따른 생존자"로 그래프 제목을 달았지만, 제목 치고 글씨가 너무 작고 강조가 되어 있지 않아 제목을 알아보기에 어렵다.
그래서 제목 글씨를 키우고, 가운데 정렬을 해서 그래프 제목이 제목답게 보이도록 만들어주자.
theme 옵션을 써서 그래프 부가적인 요소에 대한 옵션을 지정해줄 수 있다.
theme 옵션에 대해서는 line, rect, text 등 다양한 것들을 지정해줄 수 있지만, 제목과 관련된 옵션은 plot.title이므로 이것만 건드려보려고 한다. 각각 옵션에 대한 자세한 활용 방법은 아래 링크에서 확인 가능하다.
https://ggplot2.tidyverse.org/reference/theme.html
Modify components of a theme — theme
Themes are a powerful way to customize the non-data components of your plots: i.e. titles, labels, fonts, background, gridlines, and legends. Themes can be used to give plots a consistent customized look. Modify a single plot's theme using theme(); see the
ggplot2.tidyverse.org
ggplot(data = titanic, aes(x= Sex, y = Freq, fill = Survived)) +
geom_bar(stat = "identity", position = "fill") +
labs(title = "성별에 따른 생존자") +
theme(plot.title = element_text(size = 20, face = "bold", hjust = 0.5)) ## 제목 옵션
플롯의 타이틀(제목)에 들어가는 text(글자)를 건드리려고 한다. size(글자크기), face(굵게, 이텔릭 등등 폰트 옵션), hjust(정렬) 등을 지정해주었다.
좀 더 제목이 제목다워졌다. (중간에 그래프 형태도 바꾼 건 덤..)
2. 축 옵션
그래프를 그리다보면, x축에 들어가는 정보량이 많아서 그래프가 가시적으로 보이지 않을 때가 있다.
성별에 따른 생존자 그래프에서는 남/녀 두 개 항목만 들어가서 문제가 없지만, 아래 그래프 형태라면 내용 파악에 문제가 될 수 있다.
각 구끼리 글씨가 겹쳐서 알아보기 힘들다. 물론 자신이 서울시민이다, 하면 무리없이 알아볼 수는 있겠지만 디자인적으로도 예쁘지는 않다. 만약 구 정보가 가로가 아니라 세로로 쓰여있다면, 구 정보를 알아보기 편할 것 같다.
위 그래프로 디자인 옵션을 적용하면 알아보기에 편하겠지만, 저 그래프는 파이썬으로 그린 거라 디자인 옵션을 바꾸는 건 기존의 타이타닉, mtcars 데이터로 대체해서 사용한다 🤦♀️
(1) 축 각도 바꾸기
ggplot(data = titanic, aes(x= Sex, y = Freq, fill = Survived)) +
geom_bar(stat = "identity", position = "fill") +
labs(title = "성별에 따른 생존자") +
theme(plot.title = element_text(size = 20, face = "bold", hjust = 0.5)) +
theme(axis.text.x=element_text(angle=90))
마찬가지로 theme 함수를 사용할 수 있다. 이 경우 axis.text.x > angle 옵션을 사용할 수 있다. 말 그대로 각도를 조정하는 옵션이라 90도로 지정해주면 x축의 글씨를 세로로 바꾸어줄 수 있다.
이 경우 항목이 남/녀 두 개로 2가지 뿐이라 오히려 세로쓰기를 하면서 가독성이 떨어졌다. x축에 항목이 많지 않은 경우에는 가로쓰기를 유지하는 것이 가독성에 더 좋을 수 있다.
(2) x축과 y축을 바꾸기
x축에 항목이 많아 항목 식별이 어렵다면 그래프의 x축과 y축을 바꾸는 방법도 쓸 수 있다. x축과 y축을 바꾸는 옵션은 심미성을 위해서도 사용할 수 있지만, 데이터를 보여주는 분석가의 의도를 강하게 반영할 수 있기 때문에 중요하다.
ggplot(data = titanic, aes(x= Sex, y = Freq, fill = Survived)) +
geom_bar(stat = "identity", position = "fill") +
labs(title = "성별에 따른 생존자") +
theme(plot.title = element_text(size = 20, face = "bold")) +
theme(axis.text.x=element_text(angle=90,hjust=1)) +
coord_flip() ## 이거 하나면 x축과 y축을 바꿀 수 있다.
방법 자체는 간단하다. coord_flip 이거 하나만 입력하면 아래와 같이 x축에 비율이, y축에 성별이 들어가게 된다.
(1) 축 각도 바꾸기 에서는 x축의 항목이 남/녀 둘 뿐이라 사실은 의미가 없는 작업이라고 했는데,
(2) x축과 y축을 바꾸기 에서는 나름 유의미한 부분이 있다.
x축에 성별 / y축에 비율이 있을 때는 남자의 생존율이 "25%", 여자의 생존율이 "75%"네, 수치를 강조할 수 있지만
반대로 x축에 비율 / y축에 성별이 있는 경우에는 남/녀 생존율이 "엄청나게 차이나네"를 강조할 수 있다.
또 세로 막대 그래프인 경우에는 (x축을 자세히 보지 않는다면) 시간의 흐름에 따른 데이터인지, 혹은 항목을 비교하는 데이터인지 헷갈릴 우려가 있지만 가로 막대 그래프를 그릴 경우에는 그럴 우려가 현저히 줄어든다.
(3) 축 범위 조정하기
범위 옵션을 지정하지 않는 경우에도 자동적으로 그래프를 그려준다.
- 그렇지만 가령 데이터에 이상치가 있어 그 이상치 때문에 전반적인 추세가 보이지 않는 경우, 내가 원하는 범위만큼만 지정해서 그래프를 그려줄 필요가 있고,
- 혹은 특정 구간이 중요한 경우, 예를 들어 시험점수는 반드시 10점 단위로 끊어서 봐야 하는데, 그래프는 20점 단위로 끊어서 그려줬다고 하면 내가 임의로 10점 단위로 끊어서 그래프를 그려야 한다.
ggplot(data = mtcars, aes(x= hp, y = wt, color = vs)) +
geom_point(alpha = 0.5)+
scale_x_continuous(breaks = seq(0, 400, 50))
이 때는 scale_x_continuous 함수를 사용할 수 있다. (x축이 연속형 변수라 continuous)
seq 함수에서 (시작점, 끝점, 구간) 이렇게 값을 지정해주면 내가 원하는 모양으로 축 범위를 잡아서 그래프를 그려준다.
3. 레이블 달기
필요한 경우 데이터에 값 레이블을 붙여야 할 때가 있다. 만일 산점도나 선 그래프에 값 레이블을 붙여야 할 경우 ggrepel 패키지를 사용하면 레이블을 꽤나 깔끔하게 붙여준다.
ggplot(data = mtcars, aes(x= hp, y = wt, color = vs)) +
geom_point(alpha = 0.5)+
scale_x_continuous(breaks = seq(0, 400, 50)) +
ggrepel::geom_text_repel(aes(label = wt, size = 0.4))
geom_text_repel 함수에 label(어떤 값을 레이블로 붙일 것인지), size(크기는 어느정도?) 옵션을 지정해주었다.
그러면 아래와 같이 그래프를 그려주는데 값이 겹쳐서 보기 어려운 경우에는 선을 길게 빼서, 값을 보기 편하게 자동적으로 만들어준다.
4. 여러 데이터를 동시에 보여줄 때
데이터 변수 간의 관계성을 알고 싶을 때, ggpairs 함수를 쓰면 한 번에 간단하게 그래프를 그려준다.
library(GGally)
ggpairs(mtcars)
연속형 변수 vs 연속형 변수인 경우에는 산점도도 그려주고,
범주형 변수 vs 연속형 변수인 경우에는 boxplot도 그려주고, 나름대로 correlation도 계산해주는 굉장히 편리하고 좋은 라이브러리이지만..
적은 양의 데이터도 그래프를 그려주는데 시간이 오래 걸리고, 데이터의 양이 많을 경우에는 R이 뻗어버리는 경우가 왕왕 있어 이름 뿐인 필살기인 경우가 될 경우가 많다는 게 단점이다.
그래서 실질적으로 ggpair을 사용하지는 않고,(이런 필살기가 있다는 것만 알아두는 수준)
변수 별로 데이터 분포를 확인하고 싶을 때는 dplyr의 chain 함수와 ggplot을 결합하여 사용하거나
변수 간 산점도를 보고 싶을 때는 함수를 만들어 사용하는 편이다.
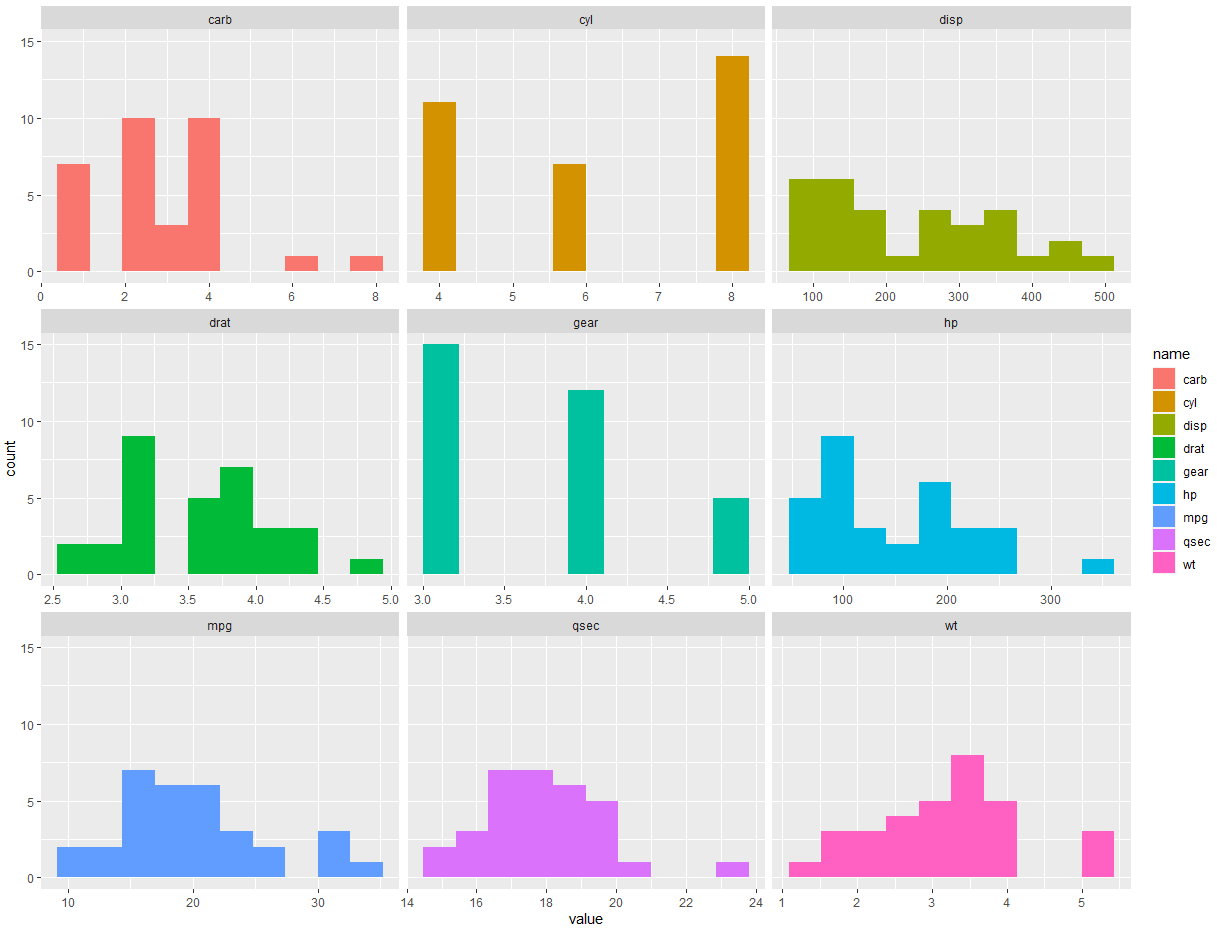
g = ggplot(data = select_if(mtcars, is.numeric) %>% pivot_longer(cols = everything()))
g + geom_histogram(aes(x = value, fill = name), bins = 10) + facet_wrap(~name, scales = "free_x")
mtcars 데이터에서 is.numeric = True, 즉 연속형 변수인 것만 골라내서 데이터를 세로로 길게 만들어준다.
value에는 값이, name에는 변수명이 들어가도록 만들어서 히스토그램을 그리는 트릭이다.
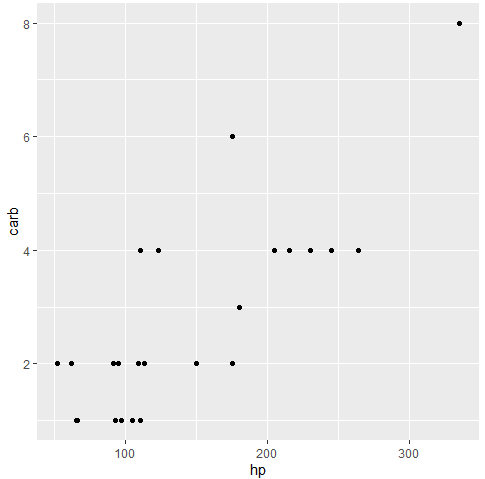
산점도를 여러 번 반복해서 그리는 것이 불편할 경우에는 함수를 만들어주기도 하는데, 한 번 함수를 만들면 원하는 변수만 넣어서 바로바로 산점도를 그릴 수 있어 편리하다.
make_dotgraph <- function(x, y){
ggplot(data = mtcars, aes(x = .data[[x]], y = .data[[y]])) + geom_point()
}
make_dotgraph("hp", "carb")