R 원툴이라 ggplot2 패키지를 사용할 일이 많은데도 불구하고, 매번 비슷비슷한 걸로 헷갈려서 한 번 정리 해보는 시간을 가져보기로 했다.
패키지 사용법을 정리하기 전에, 먼저 간단하게 준비물을 설명하자면 아래와 같다.
library(tidyverse) ## ggplot2 패키지가 내장되어 있음.
library(gridExtra) ## 여러 그래프를 한 번에 보여줄 때 사용함.
library(ggrepel) ## 레이블을 겹치지 않게 보여줄 때 사용함
library(GGally) ## 여러 변수 간 산점도를 보여줄 때 사용함.
이 중에서 사실 tidyverse 패키지만 있어도 그래프 작성에 큰 문제는 없다.
1. ggplot2 패키지 개요
분석이나 프로그래밍에 조예가 깊은 사람이라면 ggplot2 패키지의 동작 방식에 대해 잘 알 수도 있겠지만, 나는 애송이인 관계로 대략적으로 어떻게 쓰는지만 알고 있다.
참고로 R 기반의 데이터 시각화 책에서는 크게 4가지 변환 단계를 거쳐 작업이 이루어진다고 말하고 있는데,
1. 미적 매핑
2. 통계적인 변환 (stat)
3. 기하객체에 적용 (geom)
4. 위치 조정 (position adjustment)
사실 나로서는 정확히 이해는 못 해서 다음 3가지 뭉텅이(?)로 나눠서 사용하고 있다.
ggplot() + geom_...(.) + alpha
- ggplot : 어떤 데이터를 쓸 것인지에 대한 대략적인 도화지 작업
- geom : 어떤 그래프를 쓸 것인지 선택
- geom_line, geom_boxplot, geom_histogram, geom_scatter, geom_jitter 등
- 해당 옵션에서 다양한 형태의 그래프 중 어떤 그래프를 선택하여 그릴지 선택
- alpha : 필수적이지는 않지만 세부적인 디자인 작업이 필요할 경우 사용
2. 기본적인 그래프 생성
1) 데이터 불러오기
data(Titanic)
titanic <- data.frame(Titanic)
data(mtcars)
str(titanic)
str(mtcars)
# [, 8] vs Engine (0 = V-shaped, 1 = straight)
# [, 9] am Transmission (0 = automatic, 1 = manual)
mtcars$vs <- as.factor(mtcars$vs)
mtcars$am <- as.factor(mtcars$am)
head(titanic)
head(mtcars)그래프 생성을 하기 전에 앞서 시각화에 사용할 데이터를 먼저 불러온다.
초보 분석가의 벗 "titanic" 데이터와 "mtcars" 데이터를 사용하였다.
이 중 titanic 데이터는 data frame 형식이 아니라 변환을 따로 해주었고,
mtcars는 일부 변수 타입 변환을 해주었다.(범주형으로 표현되어야 할 것이 수치형으로 표현되어 있었음)
* titanic 데이터의 형태
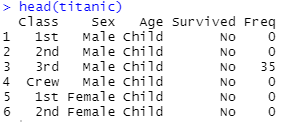
- 선실등급, 성별, 연령구분, 생존 여부별로 승객 수 집계
* mtcars의 데이터 형태
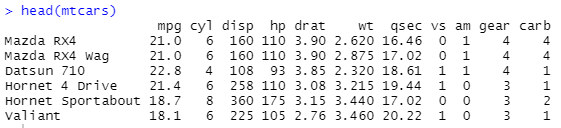
자동차 종류별로 연비, 실린더 개수, 배기량, 마력 등에 대한 정보 집계
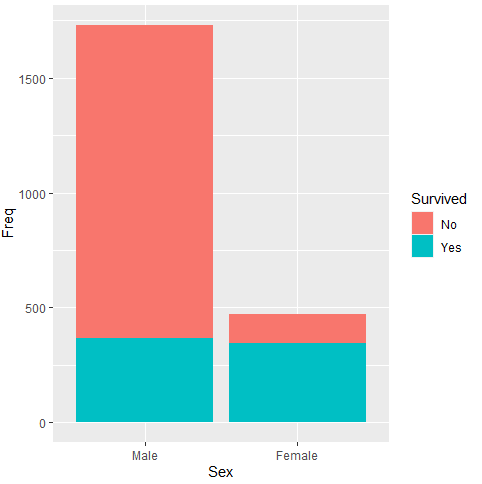
2) titanic 데이터에서 성별로 생존자 비중 그래프를 막대 그래프 형식으로 그려보고자 한다.
ggplot(data = titanic, aes(x= Sex, y = Freq, fill = Survived)) +
geom_bar()도화지 부분인 ggplot에 data, x축에 들어갈 변수, y축에 들어갈 변수, fill에 구분할 항목을 집어 넣는다.
geom(지옴) 부분에 geom_bar를 넣어줌으로써 bar 그래프로 그릴 것을 표시한다.
그러면..!

오류가 난다. stat_count can only have an x or y aesthetic 에러가 뜨는데, 이는
- geom_bar에서 stat의 기본값은 count이기 때문이고, 즉 x축 기준으로 행의 총 개수를 세어서 y축에 넣어주는데
- 내가 y축에 값을 넣어줌으로써 count가 기본인 geom_bar는 Freq를 넣으라는 거야, count를 세라는 거야 혼란에 빠져 에러를 내뱉고 마는 것이다.
조금 더 자세히 설명하면,
geom으로 지정하는 그래프에는 각각 기본적으로 집계를 수행하는 기본값이 있다. 원래는 stat 옵션에 "identity"(항등, 값을 그래도 보여줌), "count"(행의 총 개수를 셈) 등이 들어가는데, geom_bar 그래프의 기본 stat 옵션은 count고, 행의 총 개수를 세어줄 것이 아니면 stat 옵션을 지정해줘야 오류가 나지 않는다.
자세한 내용은 아래 링크를 참고!
https://ggplot2.tidyverse.org/reference/geom_bar.html
Bar charts — geom_bar
There are two types of bar charts: geom_bar() and geom_col(). geom_bar() makes the height of the bar proportional to the number of cases in each group (or if the weight aesthetic is supplied, the sum of the weights). If you want the heights of the bars to
ggplot2.tidyverse.org
stat 옵션을 수정해보자.
ggplot(data = titanic, aes(x= Sex, y = Freq, fill = Survived)) +
geom_bar(stat = "identity")
그러면 이제 오류 없이 그래프가 나온다.
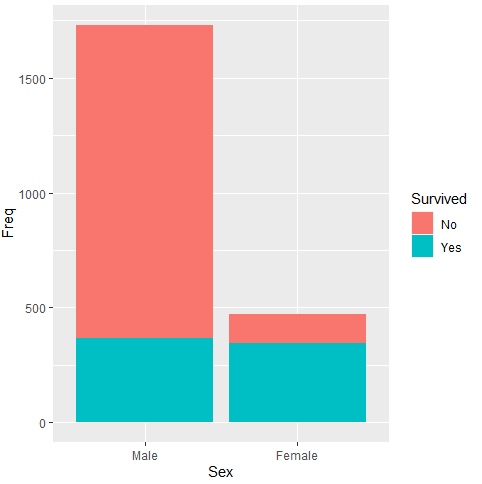
(Tip1) 그래프의 stat 옵션을 확인하자!
여성의 생존자 비중이 높게 나타난다. 그런데 남, 녀의 sample 차이가 너무 커서, 실제 어느 정도로 차이가 나는지는 잘 드러나지 않아 이를 비중 그래프로 바꾸려고 한다.
ggplot(data = titanic, aes(x= Sex, y = Freq, fill = Survived)) +
geom_bar(stat = "identity", position = "fill")
position 옵션을 추가해줬다. geom_bar 그래프의 기본 옵션은 stack으로 위 그래프에 나오는 것처럼 Survived 여부에 따라 값을 쌓아서 보여주는 것이다. 비중 그래프로 바꾸기 위해서는 position을 fill로 바꿔준다.
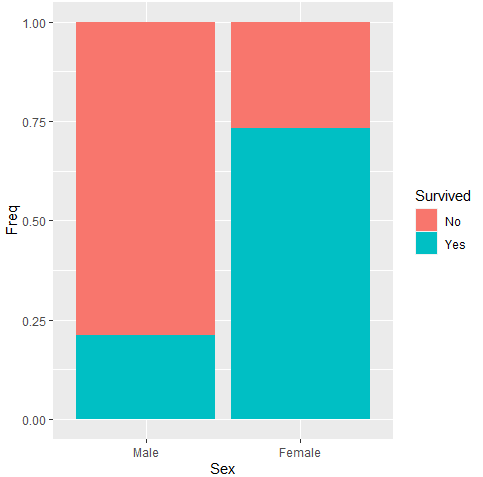
그러면 전체값 1인 비중 그래프로 바뀌게 된다. 이렇게 바꾸고 나니 성별에 따른 생존 차이가 두드러진다.
dodge 옵션을 사용하면 그래프는 다음과 같은 형태로 나온다.

(Tip2) 막대그래프의 경우 position 옵션을 통해 원하는 형태로 그래프를 바꿀 수 있다.
3) mtcars 그래프에서 vs(=엔진종류(0 = V-shaped, 1 = straight))에 따라 hp(마력) 과 wt(차량 무게) 간 관계성을 비교하려고 한다.
ggplot(data = mtcars, aes(x= hp, y = wt)) + geom_point()
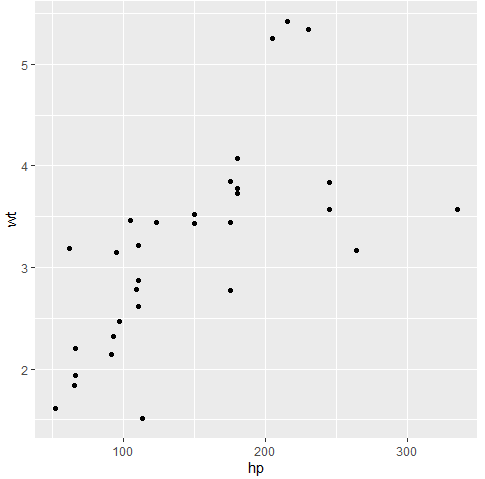
hp와 wt 변수 간 관계성이 있어보이지만 엔진 종류별로 어떻게 달라지는지는 아직까지 확인할 수 없다. 엔진 종류를 색깔로 구분하기 위해서는 color 옵션을 지정해줘야 한다.
ggplot(data = mtcars, aes(x= hp, y = wt, color = vs)) + geom_point()
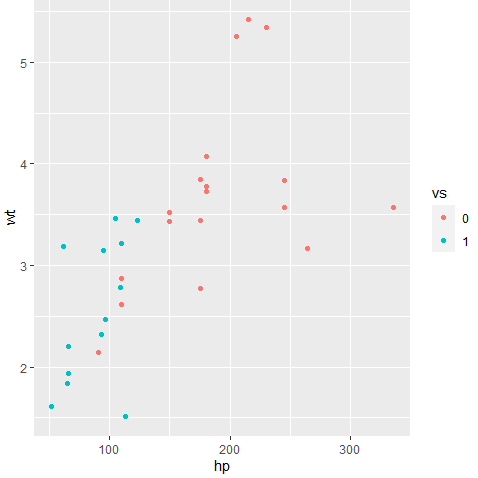
만약 크기로도 구분하고 싶다면 size 옵션도 지정해줄 수 있다.(size 옵션을 지정해주면서 점끼리 겹쳐 alpha - 투명도 조절도 같이 해주었다.)
ggplot(data = mtcars, aes(x= hp, y = wt, color = vs, size = vs)) + geom_point(alpha = 0.5)
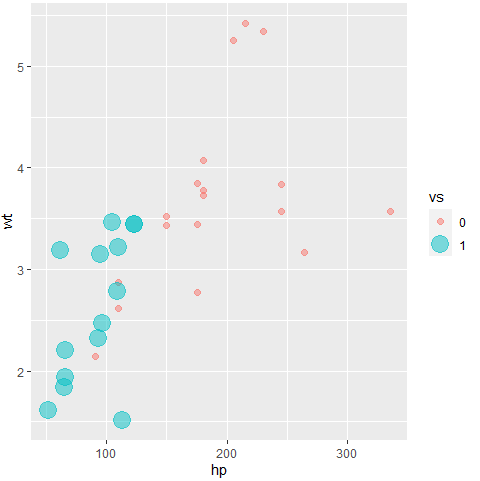
V-shaped 엔진인 경우와 straight 엔진인 경우 마력/차량 무게 간에 어느 정도 차이가 나는 것을 확인할 수 있다.
4) histogram vs boxplot vs violin plot 비교
각각의 그래프를 한꺼번에 보여주고, 비교하기 위해서는 gridExtra 패키지의 grid.arrange 함수를 사용할 수 있다.
이 중 히스토그램, boxplot, 바이올린 플롯 각각을 비교하려고 하는데, 이들 그래프는 변수에 대한 빈도 정보를 보여주기에 적합하지만, 동시에 각 그래프 별로 보여주는 정보가 미묘하게 다르기 때문이다.
a <- ggplot(data = mtcars, aes(x =am, y = hp)) + geom_boxplot(aes(fill = am)) + theme_bw()
b <- ggplot(data = mtcars, aes(x =am, y = hp)) + geom_violin(aes(fill = am)) + theme_bw()
c <- ggplot(data = mtcars, aes(x =hp, fill = am)) + geom_histogram(aes(alpha = 0.5)) + theme_bw()
grid.arrange(a, b, c)
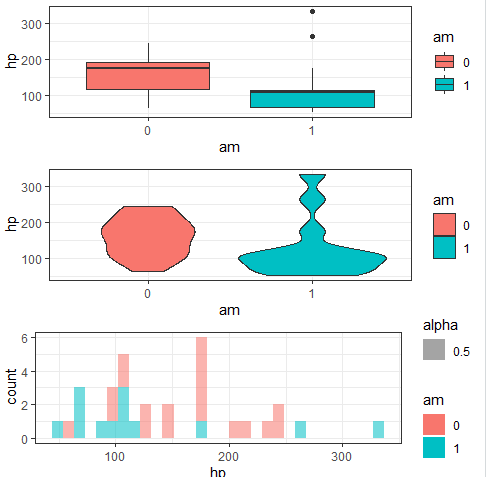
am(변속기 (0 = automatic, 1 = manual)) 종류별로 hp(마력)에 대한 빈도를 집계하였다.
- boxplot의 경우 각 분포에 대한 정보는 알려주지는 못한다. 대신 사분위수에 대한 정보를 보여준다. boxplot 그래프만 보면 automatic 변속기인 경우가 상대적으로 마력이 높은 것을 확인할 수 있다.
- violin 그래프의 경우, manual 변속기인 경우 상대적으로 마력이 낮은 차량이 더 많은 것을 확인할 수 있다.
- histogram 그래프를 보면 마력이 낮은 쪽에 분포 차량 빈도는 automatic, manual 모두 비슷해 보인다. 대신 차량의 빈도가 너무 적어서 분포 자체가 큰 의미가 있을지에 대한 고민을 하게 만든다.
쓰다보니 길어져서 일단 기본적인 그래프 작성 방법을 정리한다.
세부적인 디자인 + 각 변수별로 나눠서 그래프를 그리는 것은 다음에..!!
참고링크
https://ggplot2.tidyverse.org/reference/
Function reference
Position related aesthetics: x, y, xmin, xmax, ymin, ymax, xend, yend
ggplot2.tidyverse.org
'Tools > R' 카테고리의 다른 글
| [ADP 준비] 캐글(Kaggle) 자전거 수요 예측 문제 (1) - EDA (0) | 2021.03.07 |
|---|